
개요
트랜스포머(Transformer)는 어텐션 매커니즘을 기반으로 설계된 아키텍쳐입니다. 트랜스포머 개념이 등장한 후 말 그대로 인공지능 연구의 패러다임이 바뀌었을정도로 정말 영향력이 큰 개념입니다. 현재 공개된 GPT, 제미나이, 그록 등 텍스트 생성 모델은 모두 트랜스포머 아키택쳐 기반이고, 음성인식(Whisper), 이미지 생성(Sora) 등 정말 다양한 분야의 모델에서 사용되는 기술입니다. 트랜스포머가 왜 이렇게 좋은 성능을 보여주는지 차근차근 알아보겠습니다.
Scaled Dot-Product Attention
우선 트랜스포머를 알아보기 전에 기본적으로 알아야할 개념들 먼저 알아보겠습니다.
Scale Dot-Product Attention은 트랜스포머에서 사용되는 어텐션 매커니즘입니다.
쿼리(Query, Q)가 키(Key, K)의 유사도를 점수(Attention Score)를 계산하고, 그 확률로 벨류(Value, V)를 가중합 하는 연산입니다.
수식으로 표현하면 다음과 같습니다.
- Q: 현재 계산하려는 특정 시점의 시퀀스 벡터
- K: 모든 시퀀스의 특징을 나타내는 벡터
- V: 모든 시퀀스의 실제 데이터를 나타내는 벡터
- \(QK^\top\): 쿼리 벡터와 키 벡터를 내적(Dot-Product)해서 유사도를 계산
- \(\sqrt{d_k}\): 키 벡터의 차원 \(d_k\)의 제곱근을 나누어 내적이 차원에 비례해서 커져 발생할 수 있는 그래디언트 소실 문제를 방지
유사도 계산 후 softmax를 적용해서 총 합을 1로 만들어서 가중치를 만듭니다. 풀어서 표현하면, Scale Dot-Product는 특정 시점의 단어가 어떤 문맥에 집중해야 하는지 계산하는 과정입니다.
Self-Attention
Self-Attention은 이름 그대로 자기 자신을 참조하는 어텐션입니다. Q, K, V를 모두 같은 시퀀스에서 생성하여 시퀀스간의 연관성을 학습하는 과정입니다.
 출처: https://buly.kr/3NJaAQ5
출처: https://buly.kr/3NJaAQ5
위 사진을 예로 설명하면, 같은 두 문장을 두고 각 단어가 어떤 단어와 연관있는지 학습합니다.
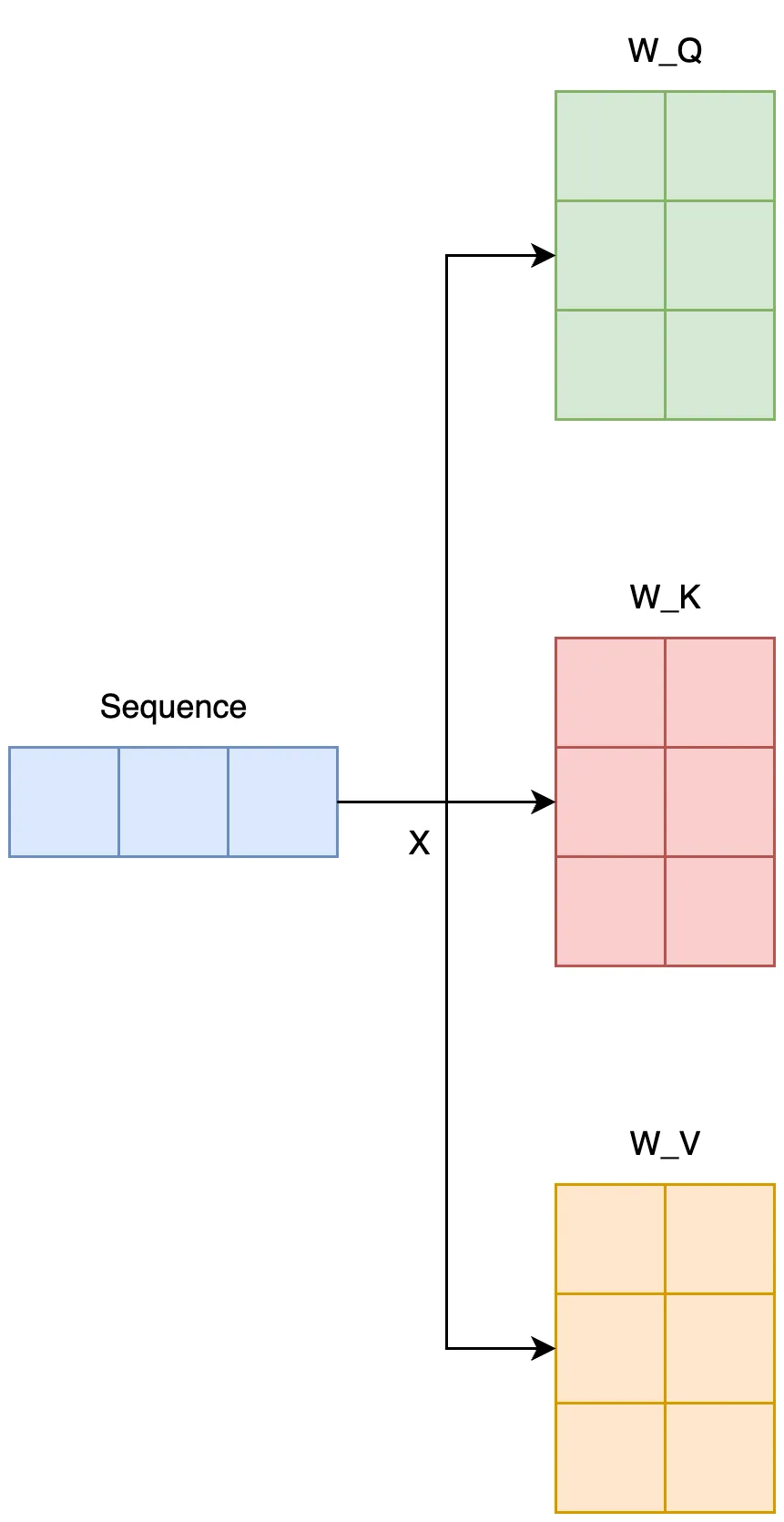
Q, K, V는 동일한 시퀀스에 각각 다른 가중치를 곱해 만듭니다. 이후 Scale Dot-Product를 진행하면 전체 시퀀스간의 유사도를 구할 수 있습니다.
Multi-Head Attention (MHA)
Multi-Head Attention은 이름 그대로 여러 헤드를 사용해서 다양한 시퀀스간의 관계를 파악하는 방법입니다.
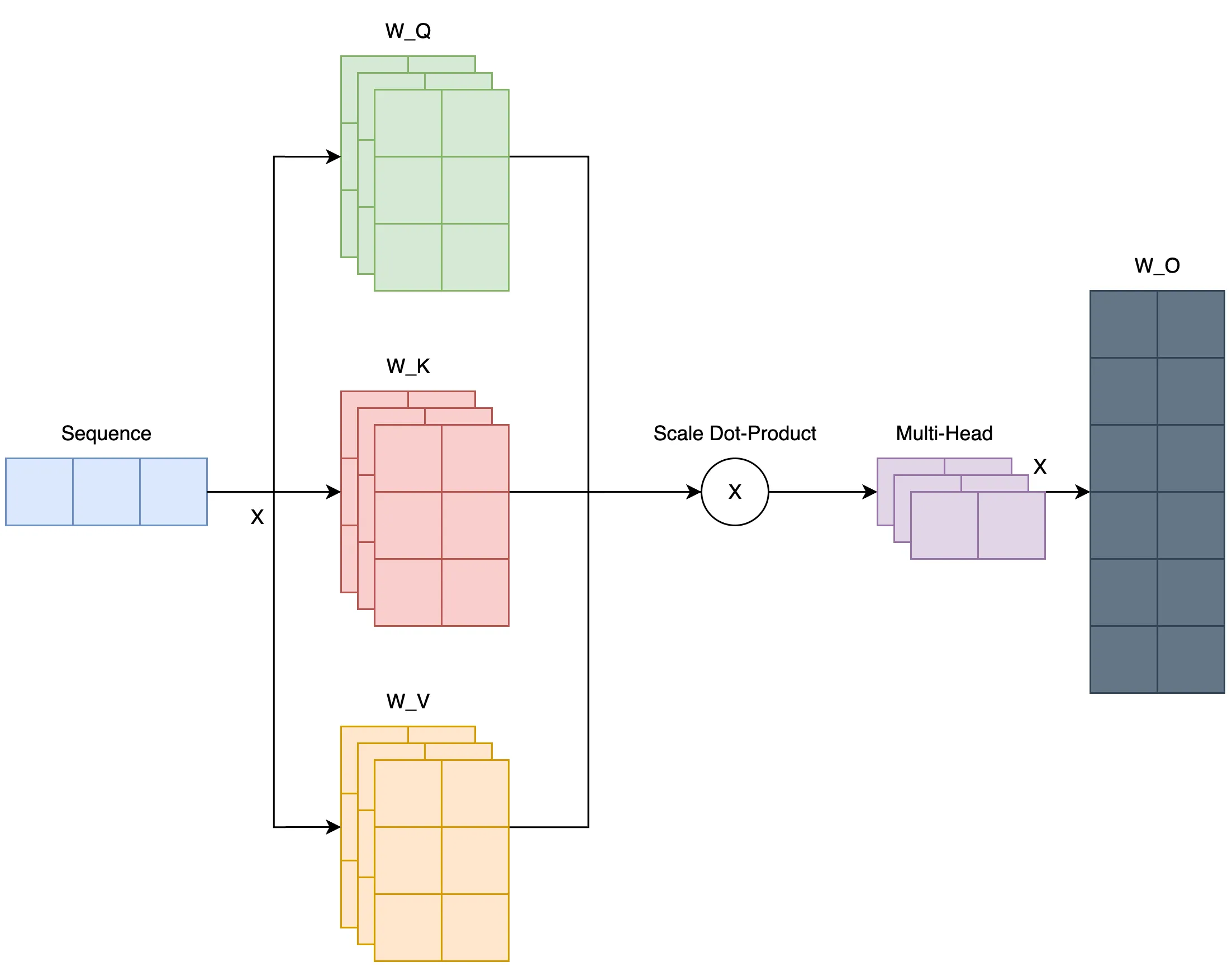
n개의 Q, K, V 세트를 만들고, n개의 Attention Score를 구한 뒤 하나로 결합(concatenate)한 뒤 가중치 행렬 \(W^O\)를 곱해 Multi-Head Attention 출력을 만듭니다.
Transformer 구조
Transformer 이해를 위한 필수 개념들을 어느정도 알게되었습니다. 이제 Transformer의 구조에 대해 살펴보겠습니다.
 출처: https://arxiv.org/pdf/1706.03762
출처: https://arxiv.org/pdf/1706.03762
위 사진은 Attention All You Need 논문에 있는 Transformer 구조입니다. 위 사진에서 왼쪽 부분이 Encoder, 오른쪽 부분이 Decoder입니다. 각 부분에 대해 자세히 알아보겠습니다.
Transformer Encoder
인코더는 입력 시퀀스의 문맥적인 표현(contextualized representation)을 만듭니다. 이는 디코더의 단어 생성에 활용됩니다. 입력부터 순서대로 알아보겠습니다.
입력시 시퀀스에는 Input Embedding 적용해서 입력 시퀀스를 벡터로 변환한 후, Positional Encoding을 적용합니다.
Positional Encoding
Positional Encoding은 시퀀스의 순서 정보를 추가하는 과정입니다. Trasnformer는 RNN처럼 순환구조가 없기때문에, 문장이 들어왔을떄 단어가 문장에 어느 부분에 위치해있는지 알지 못합니다. 그러나 문장은 같은 단어가 여러개 있더라도 위치가 바뀌면 문맥적으로 달라지는 경우가 많기때문에 위치 정보는 반드시 필요합니다. 그래서 Positional Encoding을 통해 이 문제를 해결했습니다.
Transformer에서는 Sinusoid Positional Encoding이라는 연산을 통해 수행합니다. 수식은 다음과 같습니다.
\(PE_{(pos, 2i)}=\sin(pos/10000^{2i/d_{model}})\) \(PE_{(pos, 2i+1)}=\cos(pos/10000^{2i/d_{model}})\)
전처리가 끝난 벡터는 인코더 레이어를 통해 문맥을 파악합니다.
이때 인코더 레이어는 원하는 개수대로 배치할 수 있습니다.
논문에서는 6개로 배치했습니다.
인코더 레이어는 두 개의 서브 레이어로 구성되어 있습니다.
하나는 아까 알아본 Multi-Head Attention이고, 다른 하나는 Position-wise Feed-Forward Network입니다.
Multi-Head Attnetion은 위에서 알아보았으므로 다른 하나만 알아보겠습니다.
Position-wise Feed-Forward Network
Position-wise Feed-Forward Netwok은 각 위치(position)별로 개별적으로 수행하는 Fully Connected Feed-Forward Network입니다. 이름에서 알 수 있듯이, 위치별로 독립적으로 비선형 변환을 하여 표현력을 높이는 역할입니다. 수식은 다음과 같습니다.
\[\text{FFN}(z)=max(0, zW_1+b_1)\,W_2+b_2\]수식에는 중간에 ReLU 활성화 함수가 사용되었지만, Swish 등 다른 활성화 함수도 많이 사용됩니다.
Add & Norm
그리고 인코더 레이어를 보면 중간에 Add & Norm이라는 레이어를 볼 수 있습니다. 이 레이어는 전차 연결(Residual Connection)을 통해 정보를 보존하고, 레이어 정규화(Layer Normalization)를 통해 학습 과정을 안정화 하는 역할을 합니다.
여기까지가 Transformer Encoder에 대한 분석이었습니다. 이제 Decoder를 알아봅시다.
Trnasformer Decoder
인코더에서 생성한 문맥적 표현(contextualized representation)을 이용해 원하는 결과를 만들어내는 부분입니다. 역시 순서대로 알아보겠습니다.
입력은 인코더와 비슷하게 Output Embedding으로 시퀀스를 벡터로 변환하고, Positional Encoding을 통해 위치 정보를 주입합니다.
학습시에는 시퀀스 시작을 알리는 태그 (ex.
전처리가 끝난 벡터는 디코더 레이어를 통해 원하는 답을 생성합니다.
이때 인코더 레이어와 마찬가지로 원하는 개수대로 배치할 수 있습니다.
논문에서는 인코더 레이어와 같이 6개를 배치했습니다.
디코더 레이어는 Masked Multi-Head Attention, Cross Attention, Positional-wise FFN 총 세 개의 서브레이어로 구성되어 있습니다.
Positional-wise FFN은 인코더에서 알아봤으므로 나머지 두 레이어에 대해서만 알아보겠습니다.
Masked Multi-Head Attention
디코더 입력에 대해 Multi-Head Attention을 수행하는 레이어 입니다. 다만, 다른점은 디코더 입력은 내가 예측해야할 타겟을 미리 알면 안되므로 현재 시퀀스보다 미래의 시퀀스는 지워(마스킹, Masking)버립니다. Attention Score 계산시 현재보다 미래 시점의 시퀀스에는 모두 음의 무한대(아주 작은 값)을 곱해 정보를 지웁니다.
Cross Attention
이 레이어는 Q는 이전 디코더의 서브 레이어(Masked Multi-Head Attention)에서 가져오고, K와 V는 인코더의 출력에서 가져옵니다. 이는 타겟을 만들때, 현재 디코더의 표현과 잘 맞는 인코더 시퀀스 를 참고하여 생성하는 역할을 합니다.
마지막으로 출력은 선형 변환 후 Softmax를 통해 단어를 확률적으로 예측합니다.
활용
Transformer는 현재 발표되고있는 수많은 모델들이 채택하고있는 구조입니다. T5, BART와 같이 Trnasformer Encoder/Deocer 구조를 모두 활용하는 모델도 있고, BERT, ELECTRA와 같이 인코더 구조만 활용하는 모델도 있습니다. GPT, Gemini처럼 디코더 구조만 활용하는 모델도 있습니다.
각 구조는 목적에 따라 선택됩니다.
- Encoder-Decoder 구조: 입력의 이해를 바탕으로 출력을 생성하는 테스크에서 활용됩니다. 번역, 이미지-텍스트 멀티모달과 같은 테스크에서 사용됩니다.
- Encoder-Only 구조: 토큰 분류(NER), 검색 임베딩 등 문맥 전체를 파악 하지만 생성은 필요하지 않은 모델에서 사용됩니다.
- Decoder-Only 구조: 현재 생성형 모델에 대부분 채택되는 구조로, 입력을 주면(질문) 이어서 문장을 생성(답변)하는 방식으로 사용됩니다.