
개요
RNN 구조는 이전 데이터를 기억하고 학습한다는 특징이 있어서 문장, 시계열 데이터 등 다양한 데이터를 효과적으로 학습시키는게 가능해졌습니다. 그러나 RNN으로 구성된 모델은 문장을 입력받아 분류하는 Many-to-One이나 각 시점마다 출력하는 Many-to-Many 구조만 가능합니다. 이는 입력과 출력이 다른 번역, 문장 생성과 같은 문제에서는 활용이 어렵다는 단점이 있습니다. 그래서 등장한 개념에 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) 입니다.
seq2seq
seq2seq 모델은 입력 시퀀스를 받아 다른 형태의 출력 시퀀스를 생성하는 구조입니다. 가장 대표적인 예시로는 개요에서 설명한 번역이 있습니다. 다른 언어지만 같은 뜻을 가지는 문장은 언어에 따라서 길이가 다릅니다. 그래서 seq2seq 구조를 활용하게 됩니다.
구조

seq2seq은 크게 encoder와 decoder로 구성됩니다. encoder는 문장을 입력받아 문맥을 해석하고, decoder는 해석을 바탕으로 새로운 시퀀스를 생성합니다.
Encoder
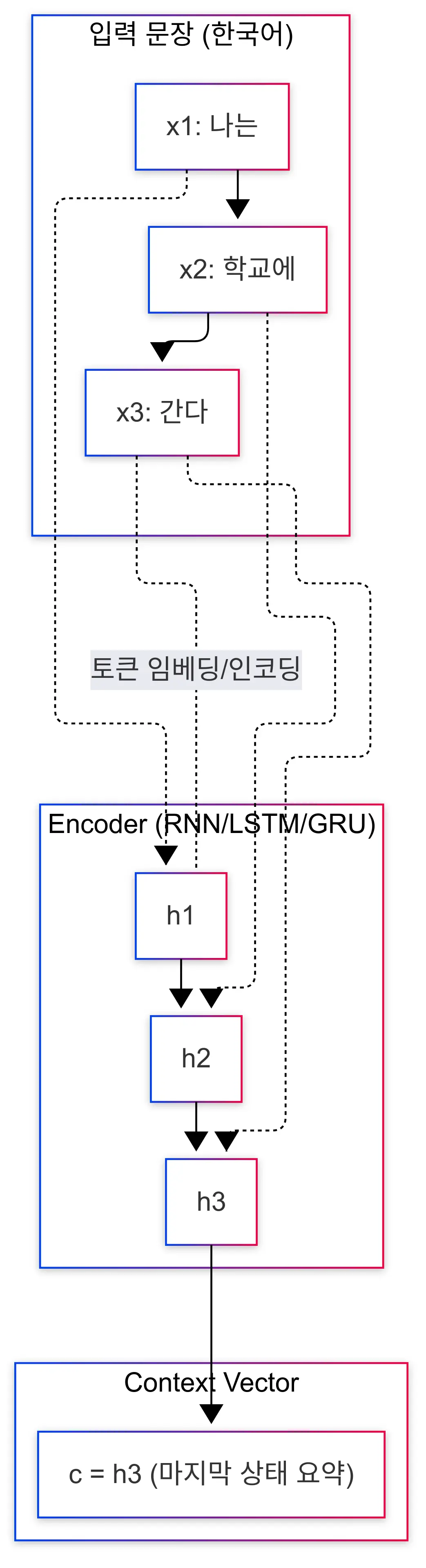
encoder는 입력 시퀀스를 RNN/LSTM과 같은 모델에 넣어서 context vector(문맥 백터)를 생성하는 역할을 합니다. 문장을 일정 단위로 잘라 (예시에서는 공백) 토큰호 한 후, Encoder에 넣어 state를 구한 뒤 압축하여 전체 의미를 담은 context vector를 생성합니다.
Decoder
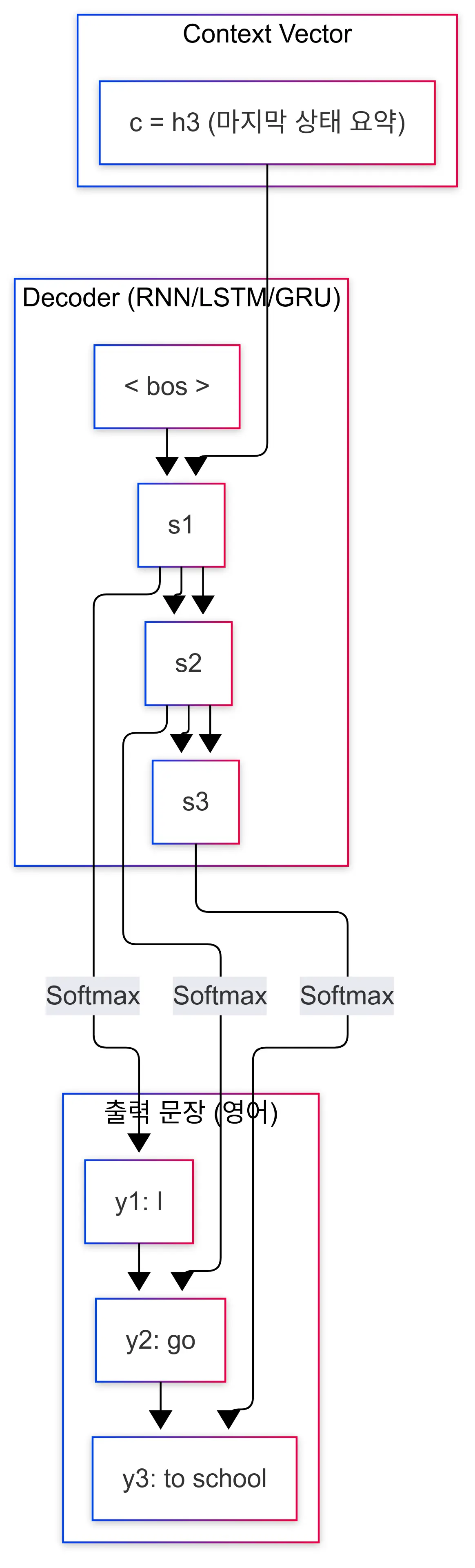
decoder는 encoder가 생성한 context vector를 입력받아 새로운 시퀀스를 생성하는 부분입니다.
이전 시퀀스와 hidden state를 활용해 다음 시퀀스를 예측합니다.
사진의 예시처럼 단어를 생성할때는 문장의 시작과 끝을 표현하기 위해
Teacher Forcing(교사 강요)
seq2seq는 학습시 Teacher Forcing이라는 방법을 사용합니다.
seq2seq도 다른 모델처럼 입력과 정답 데이터를 이용해 예측과 정답의 오차를 개선해 나가는 방향으로 학습을 진행합니다.
그러나 학습 과정에서 decoder 단어 예측은 직전 단어를 이용하게 되는데, 이때 첫 단어부터 크게 틀린 단어를 이용하게 되면 전체 예측 자체가 잘못 될 수 있는 가능성이 존재합니다.
이는 오류가 누적되어 학습이 제대로 이루어질 수 없게 합니다.
그래서 decoder에서 학습을 진행할 때 이전에 생성한 단어가 아닌 정답 데이터를 강제로 넣어 오류 누적 문제를 해결합니다.
이는 긴 시퀀스도 안정적으로 학습할 수 있도록 도와줍니다.
장점
seq2seq는 RNN구조로 해결이 어려운 여러 문제를 해결할 수 있습니다.
우선 입력과 출력의 길이가 달라도 활용이 가능합니다.
encoder와 decoder가 분리되어있기 때문입니다.
그리고 입력과 출력만 있으면 별도의 과정 없이 학습이 가능하다는것 또한 큰 장점입니다.
단점
그러나 해결이 안된 여러 문제도 있습니다.
우선 encoder도 결국 RNN/LSTM등 기존 순환신경망 알고리즘을 활용하므로 기울기 소실/폭발 문제에서 자유롭지 못합니다.
그래서 긴 시퀀스에서는 성능이 저하되는 문제가 발생합니다.
그리고 decoder가 한 단계씩 순차적으로 생성하기때문에 병렬화가 어렵습니다.
이는 큰 추론 속도가 매우 느리다는 문제를 만듭니다.
마지막으로 학습시 사용하는 교사 강요로 실제 추론시에 성능에 차이가 발생할 수 있습니다.
seq2seq 구조는 기존 RNN의 문제점을 일부 해결했지만, 여전히 완벽한 해결책은 아닙니다. 그래서 Attention이 등장하게 되었습니다. 자세한 내용은 다음 포스트에서 이어서 설명하겠습니다.