
Optimizer?
딥러닝은 오차함수(Loss Function)을 이용해 목표와 예측값의 차이를 계산하고, 최적화 알고리즘을 이용해 모델의 파라미터값을 수정해가며 학습을 진행합니다. 이때 여러 최적화 알고리즘을 Optimizer라고 합니다.
옵티마이저 종류
옵티마이저는 여러 종류가 있습니다. 오차값을 이용해 어떤 방식으로 파라미터를 업데이트 하는지에 따라 여러 방법으로 나뉩니다.
Gradient Descent (GD)
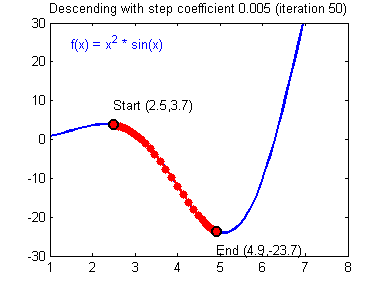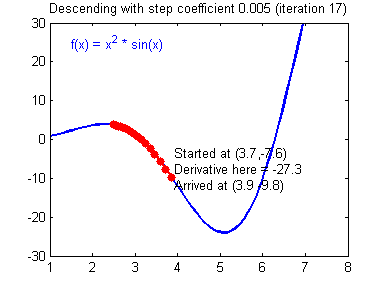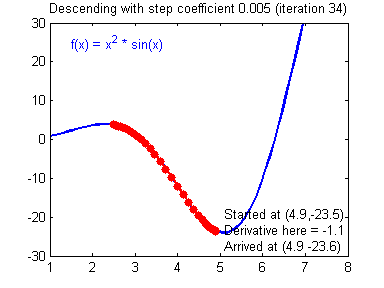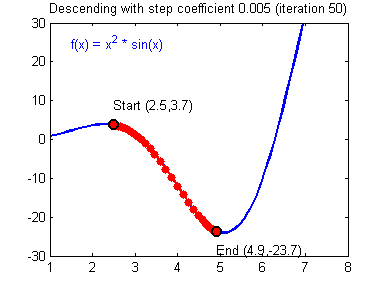 출처: https://24bean.tistory.com/entry/Gradient-Descent-Stochastic-Gradient-Descent-%EA%B0%9C%EB%85%90%EC%A0%81-%EB%B9%84%EA%B5%90
출처: https://24bean.tistory.com/entry/Gradient-Descent-Stochastic-Gradient-Descent-%EA%B0%9C%EB%85%90%EC%A0%81-%EB%B9%84%EA%B5%90

GD는 가장 기본이 되는 optimization 기법입니다. 경사하강법(Gradient Descent)라는 이름 그대로 loss와 파라미터 관계에서 최적의 부분을 경사를 따라 탐색하는 방법입니다. 모든 데이터를 이용하여 파라미터 값을 업데이트 합니다.
그러나 GD는 몇가지 단점이 있습니다. 첫 번째로 모든 데이터를 optimization에 시용하기 때문에 데이터가 많아지면 연산 비용도 늘어납니다. 두 번째로 위 gif와 수도코드에서 알 수 있듯이, 탐색 과정에서 기울기가 0이 되는 지점이 나오면 탐색이 더이상 업데이트가 진행되지 않습니다. 이러한 문제를 Local Minima 문제라고 합니다.
Stochastic Gradient Descent (SGD)

SGD는 학습에 사용되는 데이터 중 하나의 데이터만 랜덤하게 추출하여 파라미터 업데이트에 사용하는 방법입니다. 모든 데이터를 이용해서 데이터가 늘어나면 늘어날수록 느려지는 GD의 문제점을 보완하기 위해 고안된 방법입니다.
SGD는 하나의 데이터만 사용한다는 단점을 해결하기 위해 Mini-batch Gradietn Descent가 나왔습니다. 데이터를 일정한 사이즈의 batch로 나누어 각 배치에서 랜덤한 데이터를 하나씩 추출하여 업데이트에 사용하는 방법입니다. SGD 방식은 데이터를 하나만 고려한다는 점 때문에 Mini-batch 방식을 SGD로 부르기도 합니다.
그러나 이 방법 역시 Local Minima 문제를 해결하지 못했습니다.
Momentom

Momentum은 GD와 SGD에서 발생하는 Local Minima 문제를 해결하기 위해 고안된 방식입니다.
수도코드를 보면 기존 방식처럼 기울기를 구해서 바로 업데이트 하는것이 아닌 추가 과정이 있을을 확인할 수 있습니다.
추가된 수식은 EWA(Exponentially Weighted Averages)로, 과거 데이터까지 고려하여 값을 업데이트 하는 방식입니다.
\(\beta\)는 과거 데이터를 얼마나 반영할지를 결정하는 하이퍼파라미터로, 값이 크면 클수록 과거 데이터를 더욱 중요하게 반영하게 됩니다.
EWA 수식은 이전 변화량을 반영하며 일종의 관성 처럼 작용하여 Local Minma에 빠지지 않도록 도와줍니다.
만약 기울기가 0이 되더라도, 이전 변화량을 반영하므로 실제로 업데이트 되는 값은 0이 아니게 되어 게속 탐색이 가능해집니다.
Root Mean Square Propagation (RMSProp)

RMSProp은 고정적인 learning rate를 값의 변화량에 따라 변화하도록 하여 큰 변화는 작게 반영되고, 작은 변화는 크게 반영되도록 한 방식입니다.
위 방식은 탐색시 진동을 줄여주는 효과를 가져와 안정적인 학습이 가능하도록 도와줍니다.
수식을 조금 더 살펴보자면, EWA 수식을 통해 변화량을 계산하는것 까지는 Momentom 방식과 비슷합니다.
하지만 구한 변화량을 learning rate에 나누어 변화량이 크면 lr이 작게, 변화량이 작으면 lr이 크게 반영되는것을 확인할 수 있습니다.
이떄 변화량이 0이 되어 0으로 나누는 상황이 발생하면 안되기 때문에, 매우 작은 상수값 앱실론을 더해 0으로 나누는 버그를 방지합니다.
Adam

Adam은 RMSProp과 Momentum을 결합한 방식입니다.
관성을 이용해 목표 지점을 빠르게 탐색하면서도 lr을 조절하여 진동이 크지 않게 잡아주므로 빠르고 안정적인 학습이 가능합니다.
그래서 많은 학습에 Adam을 적용하면 대체로 좋은 성능을 보입니다.
수식을 자세히 살펴보면, EWA를 이용해 변화량을 계산하는 부분은 Momentum, RMSProp과 동일한 것을 확인할 수 있습니다.
그런데, \(\hat{m_t}\)와 \(\hat{v_t}\)을 구하는 수식이 추가적으로 존재합니다.
해당 수식은 bias correction을 하는 수식으로, 초기값이 0이 되지 않고 실제 데이터에 맞도록 보정하는 역할을 하는 수식입니다.
최종적으로는 bias correction을 진행한 값으로 파라미터를 업데이트하게 됩니다.
이 외에도 Adagrad, SAM, NAG 등 다양한 Optimizer가 존재하지만, 일단 가장 많이 사용되는 optimizer 위주로 정리해 봤습니다. 이 다음은 back propagation에 대해 정리해 보도록 하겠습니다.