
개요
기존에 구축된 인프라는 장기적으로는 좋지 않다고 판단하여 몇가지 작업을 진행했습니다. API서버와 DB의 분리, DB 인스턴스 숨기기, DB 모니터링 구축, DB 자동 백업 구축 순서로 진행했는데, 각 변경점에 대해 기록해보려고 합니다.
기존 인프라
우선 기존 인프라가 어떤지 보고, 어떤 문제가 있는지 분석해 보겠습니다.
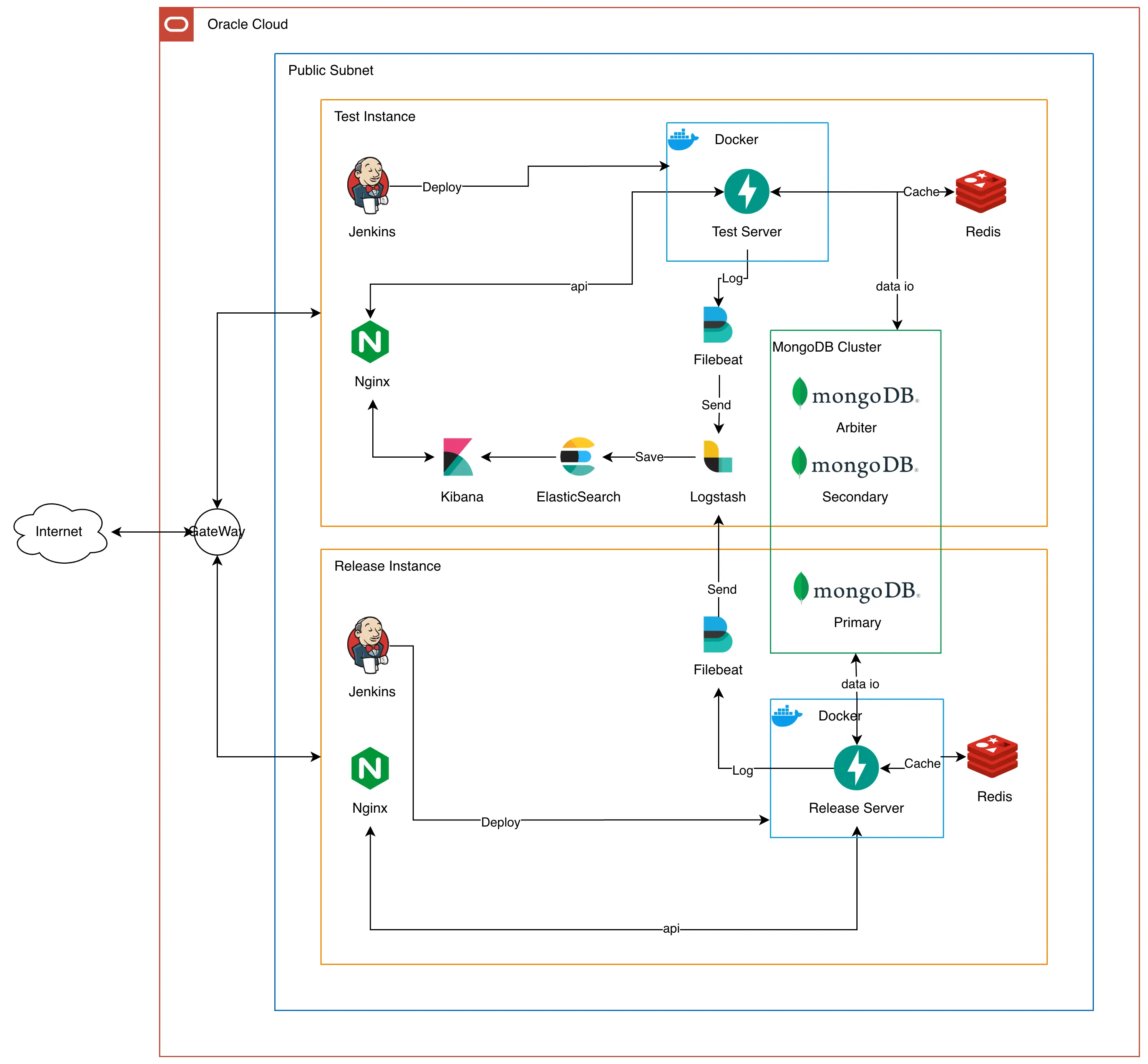
한눈에 보기에도 몇가지 문제점이 보이는데, 하나씩 짚어보겠습니다.
1. API서버와 DB가 한 인스턴스에 있음
API 서버와 DB가 한 인스턴스에 있으면 여러 문제가 있습니다.
첫 번째로는 SPOF 문제입니다. SPOF는 Single Point Of Faliure의 약자로, 직역하면 단일 장애점입니다. 만약 API서버에서 문제가 생겨서 인스턴스가 죽는다면, DB도 덩달아 같이 죽게됩니다. 이러면 문제는 API 서버에서 생겼는데, DB의 데이터 유실까지 발생할 수 있습니다.
두 번째로는 확장성의 제약입니다. 사용자가 급격히 많아지면 Scale-out을 진행하는데, 인스턴스에 DB와 API가 모두 있으면 이 작업이 굉장히 복잡해집니다. 기존과 똑같이 DB까지 모두 넣은 인스턴스를 새로 만들고 서비스에 적용하려면 기존의 데이터를 새로운 DB에 모두 동기화 해야합니다. 이는 효과적인 Scale-out을 진행할 수 없게 만듭니다.
세 번째로는 보안 취약성입니다. API서버는 사용자에게 공개되어야 하기 때문에 public ip를 갖고 공개됩니다. 만약 해커가 성공적으로 API 서버에 접근하게 된다면, DB까지 위협을 받게 됩니다.
2. MongoDB Cluster가 불완전함
기존 인프라는 서버 비용을 줄이기 위해 테스트 서버에 MongoDB Cluster의 Secondary와 Arbiter를 둘다 뒀습니다. 그러나 이 방법은 MongoDB의 replica 장점을 전혀 사용할 수 없는 형태입니다.
MongoDB의 Replica Set은 Primary, Secondary를 두고 지속적으로 데이터를 동기화 하며 유지하다가 둘중 하나가 죽으면 Arbiter와 살아남은 노드가 투표하여 새로운 Primary를 선출하는 방식으로 고가용성을 제공합니다. 그래서 MongoDB는 Replica Set을 사용할때는 3, 5, 7 등 홀수 단위로 이용하기를 권장하는데, 투표로 과반수를 넘기게 하기 위해서 입니다.
그런데 지금 구성은 만약 테스트서버가 잠깐 점검으로 내려가거나 아예 죽으면 대응이 안되는 구조입니다.
개선된 인프라
개선된 인프라는 다음과 같습니다.
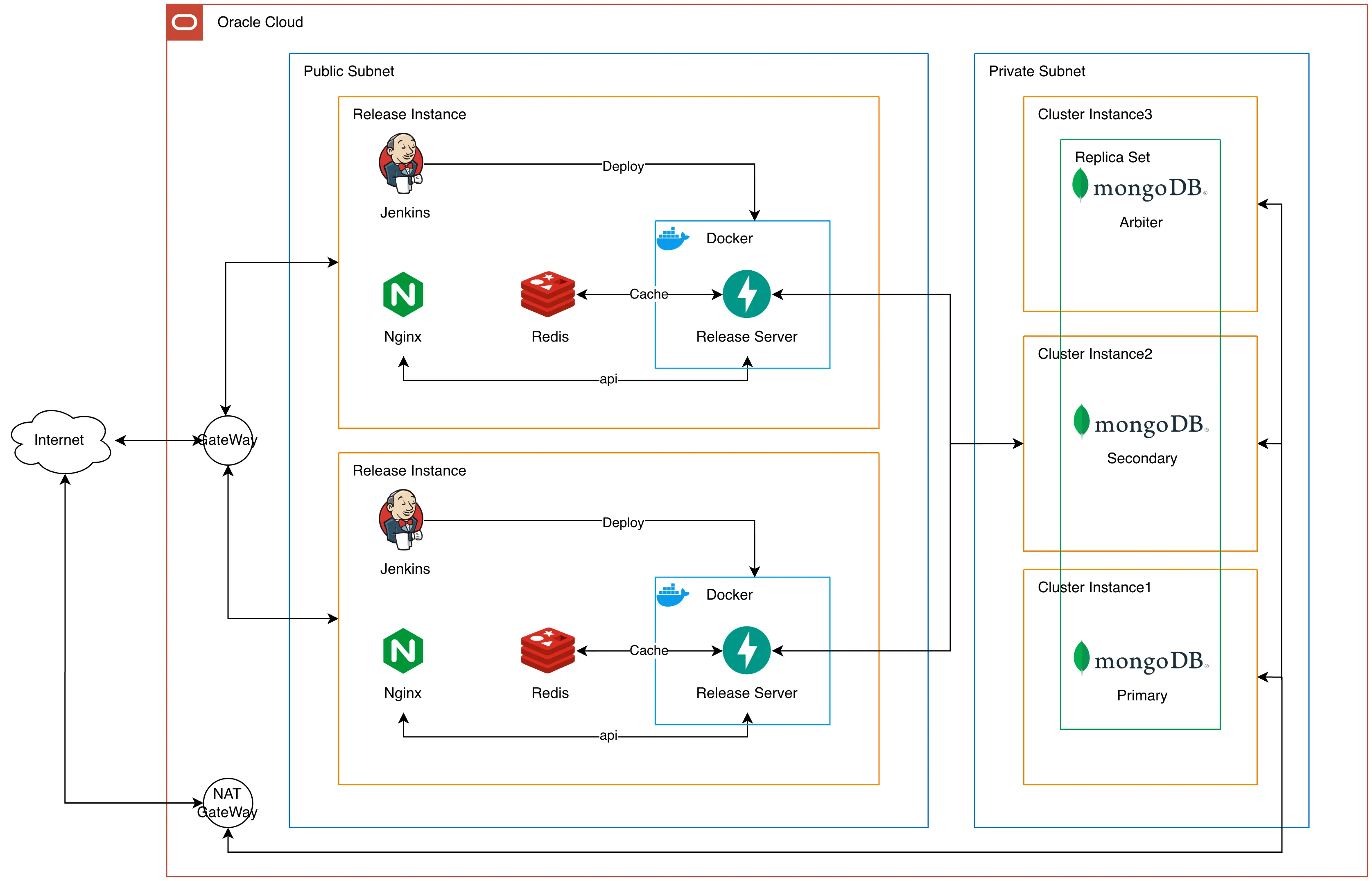
가장 큰 차이는 DB입니다. 기존과 다르게 DB를 API서버와 분리하고, Private Subnet으로 외부에 직접 노출되지 않게 만들었습니다. Private Subnet은 외부와 직접 통신을 못하기 때문에 NAT Gateway를 추가하여 내부에서 외부로의 요청 및 응답은 가능하도록 했습니다.
레플리카셋 구성도 각 노드당 하나의 인스턴스를 두어 기존의 문제점인 레플리카셋을 활용하지 못한다는 문제를 해결했습니다. 인프라 재구축 과정에서 운영중인 MongoDB를 그대로 새로운 DB에 마이그레이션해야 했는데, 이는 ReplicaSet에 노드를 추가했다가 새로운 Primary를 강제로 설정하고, 기존 노드를 지우는 방식으로 진행했습니다.
해결이 되지 않은 문제
개선되었다는 인프라를 보면 무언가 이상한 부분이 있습니다.
바로 API서버에 Redis와 Jenkins가 아직 같이 있다는 부분입니다.
물론 해결 방법은 생각보다 간단합니다. Jenkins는 테스트서버에 설치된 Jenkins를 이용해서 배포하게 하면 해결될거 같아서 곧 수정을 진행할 예정입니다. Redis도 MongoDB처럼 전용 인스턴스를 만들어 분리하면 문제를 해결할 수 있습니다.
그러나 비용이라는 현실적인 이유로 일단은 그대로 뒀습니다. 그리고 다른 글에서 설명하겠지만, 부하테스트를 진행해보니 개선된 인프라로 버틸 수 있는 규모에 비해 사용자 수는 매우 적어서 아직까지는 그대로 둬도 되겠다고 판단했습니다.
DB 모니터링하기
DB를 분리하는 작업을 진행하는김에 DB를 실시간으로 모니터링하고 기록할 수 있는 시스템도 구축했습니다. 기존에는 MongoDB Compass에서 제공하는 Performance Metric 기능으로 실시간 ops/s와 같은 지표를 봤는데, 기록이 안되다보니 구축이 필요하다고 느꼈습니다. 그래서 각 DB 인스턴스에 mongodb exporter와 node exporter를 설치해서 MongoDB 상태와 인스턴스 상태를 수집하고, 테스트 서버에 Prometheus를 설치해 지속적으로 DB와 인스턴스 상태를 가져와 저장, 이전에 구축한 Grafana를 통해 시각화 하는 방법으로 DB 모니터링 시스템을 구축했습니다.
MongoDB Exporter/Node Exporter
MongoDB Exporter는 주기적으로 DB에 접속하여 상태를 수집합니다. 수집하는 항목은 초당 쿼리 처리 수(OPS), 연결된 클라이언트 수, relication lag, replica node 상태 등 다양한 지표가 있습니다. MongoDB Exporter는 직접 DB에 접속해서 데이터를 가져와야 하기 때문에 MongoDB Exporter가 사용할 계정이 따로 있어야 합니다.
Node Exporter는 주기적으로 커널의 상태를 수집합니다. CPU 사용량, 메모리 사용량, 디스크 I/O, Network 등 다양한 지표를 수집합니다.
Exporter는 직접 데이터를 저장하지 않고, 다른 누군가 요청하면 데이터를 제공하는 방식입니다.
Prometheus
Prometheus는 다른 누군가 보낸 데이터를 받는(Push)게 아닌 직접 데이터를 요청해서(Pull) 가져옵니다. 그래서 Node/MongoDB Exporter가 각자 로그 데이터를 만들고, Prometheus가 요청하면 데이터를 제공하는 방식으로 구성됩니다.
Prometheus도 Loki처럼 다양한 레이블을 붙여 관리가 가능하고, LogQL처럼 PromQL을 이용해서 데이터를 질의합니다. 두 저장소에 저장된 데이터는 모두 Grafana를 통해 시각화가 가능합니다.
Prometheus 설정은 매우 간단해서 설정에 대한 설명은 생략하도록 하겠습니다.
DB 모니터링 대시보드
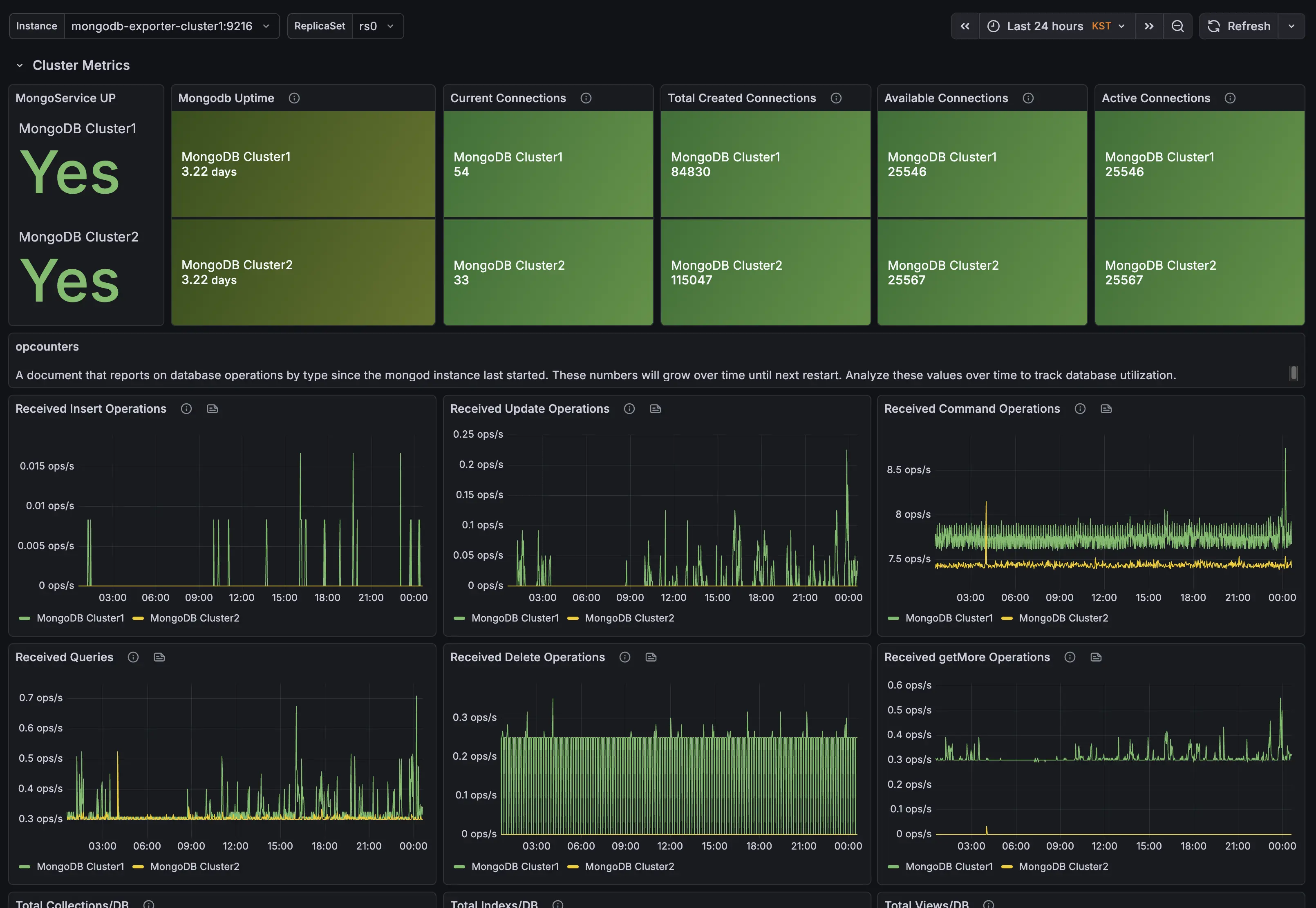
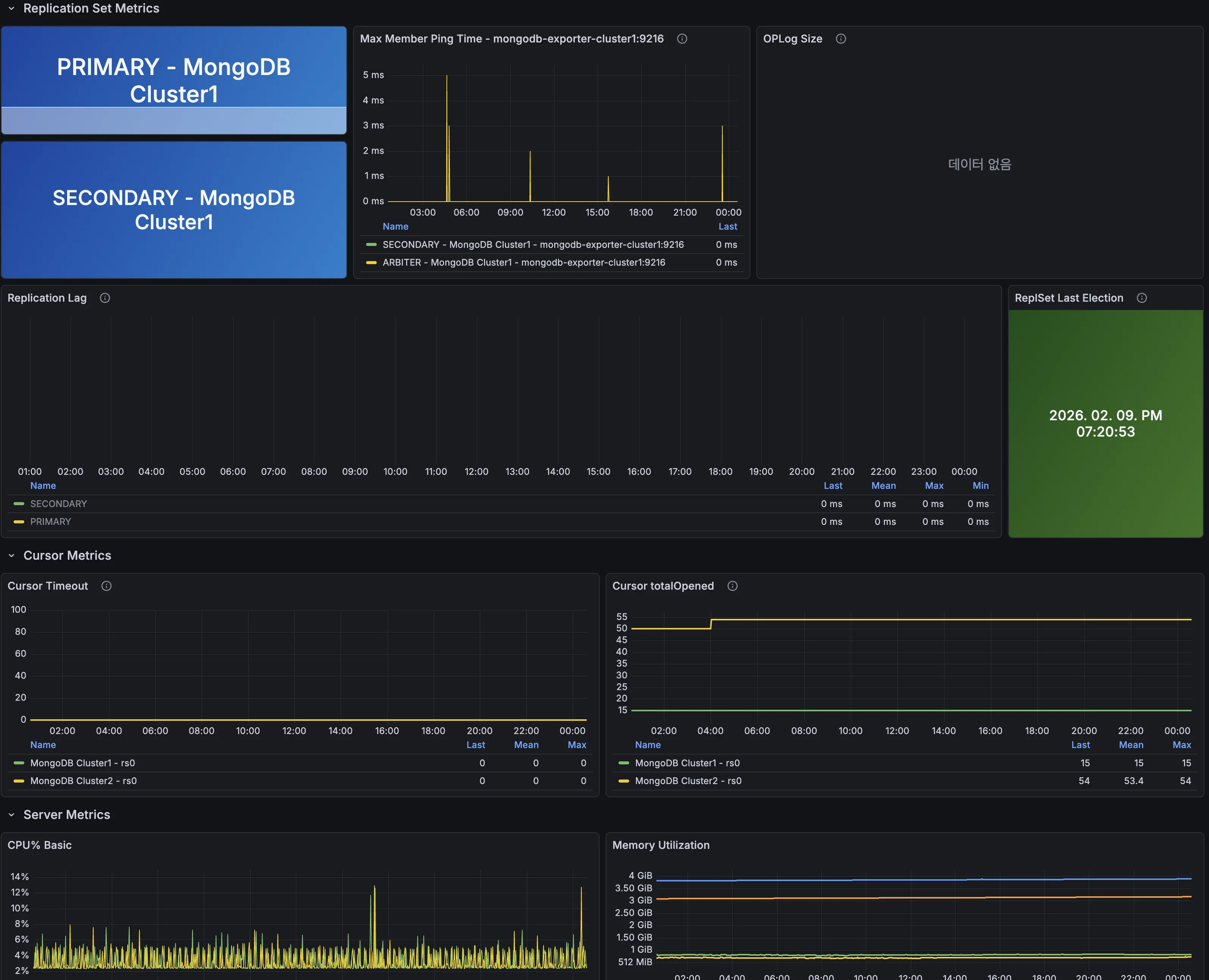
Exporter와 Prometheus를 이용해 수집한 데이터를 보여주는 대시보드 입니다. OPS, 레플리카셋 상태, 각 DB 인스턴스의 상세 정보를 확인 가능합니다. Arbiter 정보는 수집하지 않는데, Arbiter는 데이터를 저장하지 않기 때문에 따로 Exporter를 설치하지 않았습니다.
DB 백업하기
마지막으로 DB의 정기적인 자동 백업을 구축했습니다. 어느덧 서비스의 가입자기 1,600명을 넘겼는데, DB 인스턴스가 한번에 죽을걸 대비해서 백업이 필요하다고 느꼈습니다.
MongoDB 백업 방식에는 크게 두 가지가 있습니다.
mongodump
mongodump는 MongoDB에 기본적으로 포함되어있는 유틸리티입니다. MongoDB의 데이터를 BSON으로 추출하여 데이터를 복제해 저장해 두었다가 필요하면 mongorestore로 복구가 가능합니다.
별도의 설치 없이 바로 사용이 가능하고 간편하다는 장점이 있지만, 복원시 인덱스를 다시 생성하기 때문에 복원 속도가 매우 느리다는 단점이 있습니다.
Percona Backup for MongoDB (PBM)
PBM은 Percona에서 만든 MongoDB 백업 솔루션입니다. PBM은 최초에는 전체 스냅샷을 찍어 저장하고, 이후부터는 달라진 부분만 추적하여 기록하는 증분백업을 지원합니다. 그래서 대규모 DB 백업에 적합한 솔루션입니다.
게다가 PBM 레플리카셋, 샤딩과 같은 환경에서도 데이터 충돌 없이 알아서 백업을 진행합니다.
그러나 PBM은 초기 설정이 복잡하고, 자원을 많이 소모한다는 단점이 있습니다. 공식 권장도 최소 2코어 이상, 4gb 이상을 확보하고 PBM을 적용할것을 권장하고 있습니다.
저는 두 방법을 고민하다가 mongodump를 선택했습니다. 아직 DB 데이터 규모가 MB 수준이라서 mongodump도 몇십초면 끝나기 때문입니다.
Object Storage 업로드
mongodump는 기본적으로는 인스턴스 스토리지 안에 저장이 됩니다. 이 방식은 인스턴스에 문제가 생기면 백업 데이터도 함께 증발할 수 있습니다. 그래서 dump가 완료되면 OCI의 Object Storage에 자동으로 업로드 되도록 만들었습니다.
이 모든 과정을 쉘스크립트로 작성하고 crontab에 넣어서 매일 한국 시간으로 오전 4시가 되면 백업 후 Object Storage에 자동으로 저장되게 만들었습니다.
여기까지가 DB를 분리하면서 모니터링과 백업까지 진행한 과정입니다. 다음 글은 지금까지 구축한 모니터링 체계를 이용해서 부하 테스트를 하고 최적화 하는 과정에 대한 글 입니다.
앱 다운받기