
간단하게 머신러닝(딥러닝)에 대해 정리해보는 글 입니다. 딥러닝에 대해 간단한 원리와 용어 정리같은 느낌의 글이라서 자세한 내용은 추후에 각각 추가적인 포스팅으로 하나하나 자세히 다뤄볼 예정입니다.
머신러닝? 딥러닝?
인터넷에 관련 정보를 찾아보다보면 많은 사람들이 인공지능, 머신러닝, 딥러닝을 혼용해서 사용합니다. 하지만 각 단어는 모두 뜻이 다릅니다.
정확히 말하면 인공지능 > 머신러닝 > 딥러닝 순으로 하위 개념입니다.
- 인공지능: 인공지능은 인간의 지능을 기계로 구현하는 모든것을 포괄하는 개념입니다.
- 머신러닝: 머신러닝은 컴퓨터에게 일일이 프로그램되지 않고도 스스로 학습이 가능한 프로그램/기계를 만드는 방법을 설명하는 분야입니다.
- 딥러닝: 머신러닝의 한 방식으로, 인간의 뇌 신경망을 모방하여 학습을 시키는 분야입니다.
딥러닝 학습 원리
그렇다면 딥러닝은 어떻게 인간의 뉴런을 모방할까요? 딥러닝 학습 과정을 간략하게 설명드리겠습니다.
선 긋기
딥러닝의 목적을 간단하게 말해보자면 ‘선 잘 긋기’ 입니다.
여기 x는 일 한 시간, y는 벌어들인 돈 관계를 가진 데이터가 있습니다.
각 데이터는 (25, 10), (8, 6), (18, 9) 입니다.
이를 그래프 위에 표현하면 다음과 같습니다.
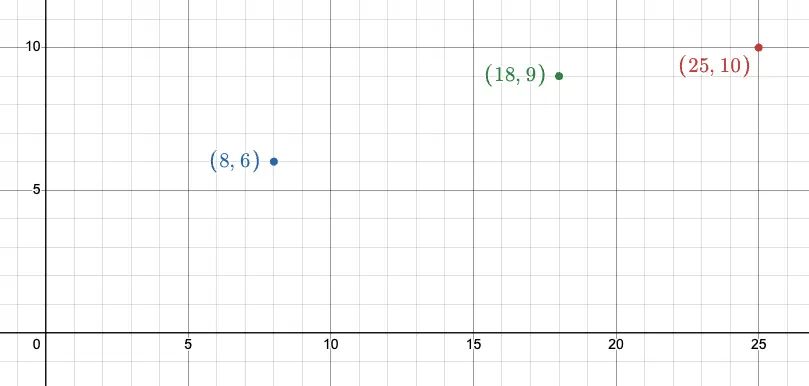
그렇다면 일 하는 시간이 주어지면 벌어들일 돈을 어떻게 예측할 수 있을까요?
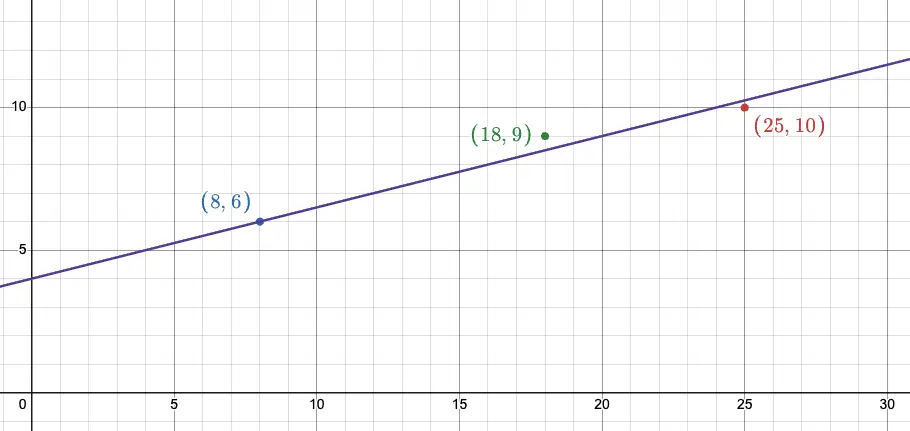
방법은 간단합니다. 위 세 데이터를 가장 잘 표현하는 직선을 그리고, 직선의 x좌표를 통해 y좌표 값을 구하면 됩니다. 예를 들어 일 한 시간이 12시간일때는 7 만큼 벌 수 있다고 예측이 가능합니다. 이러한 예측 방식을 회귀라고 합니다.
그렇다면 데이터를 분류 해야하는 문제는 어떻게 학습할까요? 다음과 같은 데이터 분포가 있다고 가정해 봅시다.
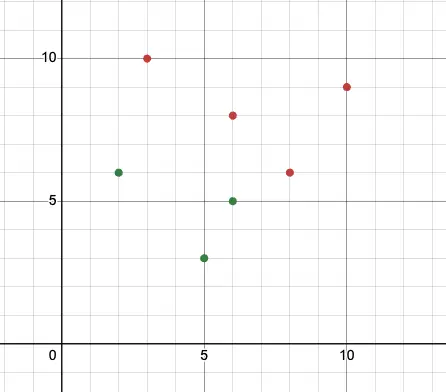
색깔이 같은 데이터는 같은 라벨을 가진 데이터 입니다. 이 상황에서 데이터가 주어지면 어떤 라벨에 포함되는지 어떻게 알 수 있을까요?
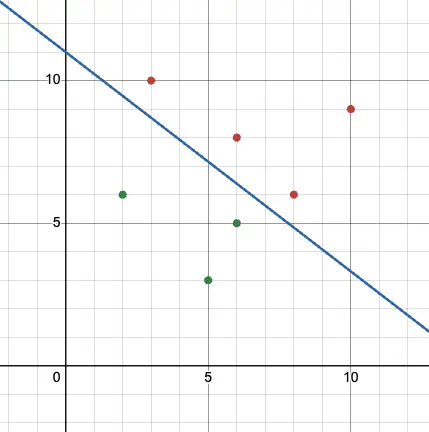
이렇게 두 영역을 가르는 직선을 그으면 됩니다. 위 직선의 아랫 부분은 초록색 라벨, 윗 부분은 빨간색 라벨이 포함된 영역이라고 판단하는 것이죠. 이러한 예측 방식을 분류라고 합니다.
위 두 방식에서 알 수 있듯이 데이터 예측을 위해 선을 긋는 작업을 진행합니다. 그렇다면 딥러닝 과정에서 가장 잘 예측되는 선을 어떻게 그을까요?
가장 좋은 선 긋기
직선을 수식으로 표현하면 다음과 같습니다.
\[y = ax + b\]이때 a는 기울기(weight), b는 편향(bias)이라고 합니다. 학습을 진행할 때 두 값을 계속 수정해가며 주어진 데이터를 얼마나 잘 분석할 수 있는지 판단합니다. 그리고 어느정도 오차가 있는지 확인 후, 오차를 바탕으로 값을 조정헤 나갑니다. 이 과정을 오차가 가장 적어질 때 까지 반복해서 학습을 진행하게 됩니다.
오차 함수
오차함수는 내가 그은 직선과 주어진 데이터 간의 오차가 어느정도 되는지 판별하는 함수입니다. 학습 방식, 데이터 특성에 따라 MSE, RMSE, Binary Crossentropy 등 다양한 오차함수가 사용됩니다. 오차함수에 대한 자세한 내용은 추후에 따로 포스팅 할 예정입니다.
경사하강법
오차함수를 통해 오차를 계산했으면, 그 오차값을 통해 기울기와 편향 값을 수정해야 합니다. 이때 사용하는 방법을 경사하강법 이라고 합니다. 왜 경사 하강법으로 불리는지 아래 gif를 보시면 한번에 이해가 가능합니다.
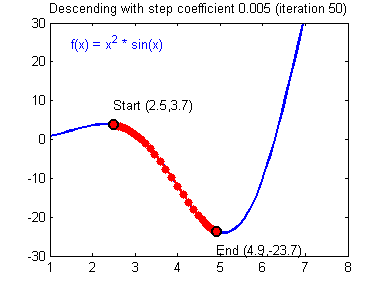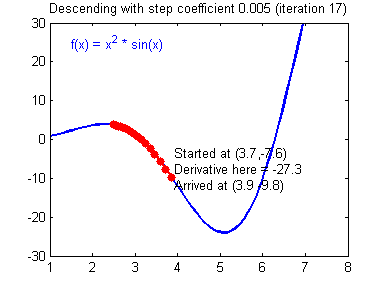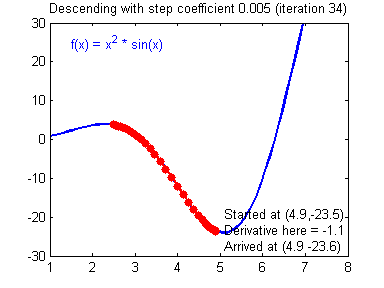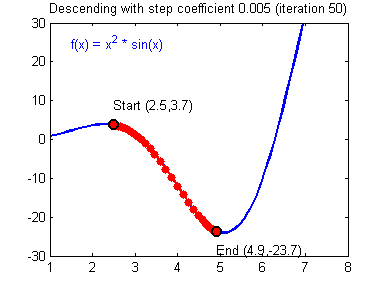 출처: https://24bean.tistory.com/entry/Gradient-Descent-Stochastic-Gradient-Descent-%EA%B0%9C%EB%85%90%EC%A0%81-%EB%B9%84%EA%B5%90
출처: https://24bean.tistory.com/entry/Gradient-Descent-Stochastic-Gradient-Descent-%EA%B0%9C%EB%85%90%EC%A0%81-%EB%B9%84%EA%B5%90
위 gif는 경사하강법이 어떻게 동작되는지 잘 시각화한 자료입니다.
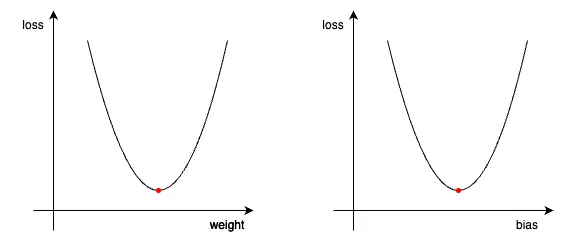
각각 기울기-오차, 편향-오차 관계를 그래프로 표현 후, 기울기가 0이 되는 지점(극소값)을 찾는 과정입니다.
이렇게 어떤 방법으로 어느정도 움직여서 극소값을 찾을지 결정하는 역할을 옵티마이저(Optimizer)라고 합니다. 경사하강법은 그중 가장 기본적인 방법으로, SGD, Adam, RMSProp 등 다양한 방법이 있습니다. 옵티마이저에 대한 내용은 추후에 따로 포스팅 할 예정입니다.
퍼셉트론
오차를 수정해나가는 방법은 알았습니다. 그럼 딥러닝의 목적인 인간의 뇌를 모방하는건 어떻게 할까요? 바로 퍼셉트론 입니다.
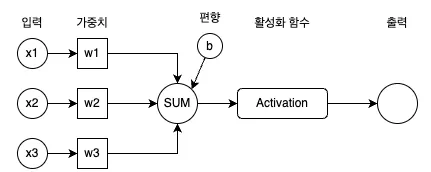
퍼셉트론은 위와같은 구조를 가지고 있습니다.
입력이 들어오면 각 입력에 가중치를 곱해줍니다. 어느 정보를 더 중요하게 판단할지 결정하는 과정입니다.
그 다음 가중치를 곱한 입력값과 편향을 더해줍니다. 위 과정을 식으로 나타내면 다음과 같습니다.
식을 보면 알겠지만 퍼셉트론에서 가중치와 바이어스가 학습 과정에서 최적에 값으로 업데이트 될 것이라고 유추할 수 있습니다.
마지막으로 이렇게 계산된 값을 바로 출력으로 내보내지 않고, 활성화 함수(Activation Function)을 거쳐 어느정도 출력으로 내보낼지 결정합니다.
활성화 함수
활성화 함수는 신호의 세기를 조정하는 함수입니다. 우리 뇌의 일정 임계치를 넘는 신호만 전달하는 시스템을 모방한 함수입니다. 활성화 함수 역시 데이터 특성, 알고리즘 특성에 따라 ReLU, Sigmoid 등 다양한 함수를 사용합니다. 활성화 함수에 대한 내용도 추후 따로 포스팅 예정입니다.
다층 퍼셉트론
그런데 퍼셉트론에는 한가지 문제가 있습니다. 바로 XOR 문제 입니다.
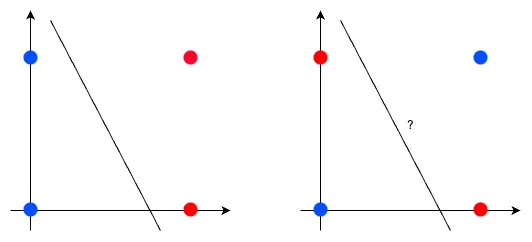
위 그림처럼 직선으로는 분류가 되지 않는 경우가 있습니다. 이럴때는 어떻게 해야할까요?
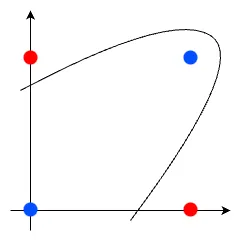
바로 선을 휘어서 그리는 방법입니다. 그런데 어떻게 선을 휘게 만들까요?
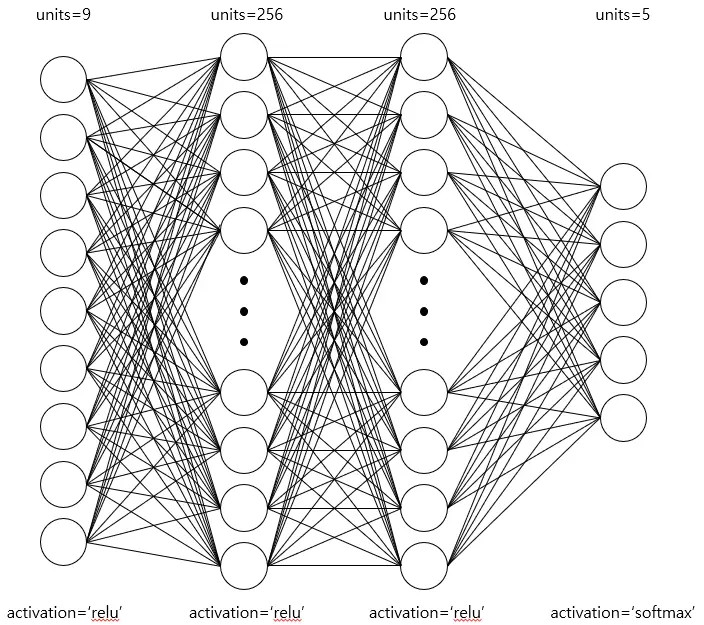
바로 퍼셉트론 구조를 여러층으로 쌓는 다층 퍼셉트론입니다. 구체적으로 왜 다층 퍼셉트론이 XOR 문제를 해결하는지는 추후 따로 포스팅 예정입니다.
오차역전파
이제 학습하는 구조까지 알았습니다. 이제 마지막 과정이 남았습니다. 오차를 이용해 그 많은 가중치와 편향값을 업데이트 하는 작업이죠. 이러한 작업을 오차역전파라고 합니다. 이름에서 알 수 있듯이, 오차를 출력층부터 입력층까지 거꾸로 전파하는 과정입니다. 자세한 원리는 추후 따로 포스팅 예정입니다.
뭔가 생략된게 많지만, 오늘은 딥러닝의 흐름정도만 알아보는 시간이니 이정도만 설명하겠습니다. 앞으로 각각의 세세한 부분을 다루는 글과, CNN, RNN 등 다양한 알고리즘에 대해 설명하는 글도 작성할 예정입니다.