
오차함수?
오차함수(loss function)은 컴퓨터가 예측한 선이 얼마나 데이터를 잘 표현하는지 판단할때 사용하는 수식입니다.
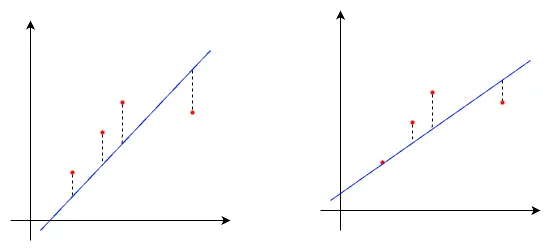
데이터를 잘 표현했다면 오차가 작고, 그렇지 못하다면 오차가 크죠. 딥러닝에서는 오차값을 이용해 오차역전파(back propagation) 과정을 거쳐 모델의 가중치와 편향을 더 잘 예측할 수 있도록 업데이트 할때 사용합니다.
회귀 오차함수 종류
오차함수는 여러 종류가 있습니다. 학습의 형태(회귀, 분류, 다중분류 둥)에 따라, 데이터 특성에 따라 다양한 오차함수 중 알맞은 오차함수를 선택해서 사용하게 됩니다. 이번에는 회귀 학습에 사용하는 오차함수에 대해 알아보겠습니다.
평균 절대 오차 (MAE, Mean Absolute Error)
\[\text{MAE} = \frac{1}{N} \sum_{i = 1}^{n} \lvert \hat{y_i} - y_i \rvert\]- \(n\): 데이터 수
- \(y_i\): 실제 값
- \(\hat{y_i}\): 예측 값
- \(\lvert \hat{y_i} - y_i \rvert\): 오차의 절대값
MAE는 예측값과 정답값의 차이를 모두 양수로 바꾼 후 평균을 내는 방식으로 오차를 산출합니다.
특징
- 오차의 절대값을 모두 더해 평균으로 계산해서 직관적인 해석이 가능합니다.
- 오류값에 대해 선형적인 반응을 보입니다.
- 모든 오차를 동일한 중요도로 취급합니다.
단점
- 모든 오차를 절댓값으로 처리하기 때문에 미분 불가능한 지점이 생길 수 있습니다. 이는 경사하강법을 이용해 최적의 값으로 업데이트하는 과정에 문제가 발생할 수 있습니다.
- 모든 오차를 선형적으로 받아들이므로 최적의 값에 대해 수렴이 느립니다.
평균 제곱 오차 (MSE, Mean Square Error)
\[\text{MSE} = \frac{1}{N} \sum_{i = 1}^{n} (\hat{y_i} - y_i)^2\]- \(n\): 데이터 수
- \(y_i\): 실제 값
- \(\hat{y_i}\): 예측 값
- \((\hat{y_i} - y_i)^2\): 오차의 제곱
MSE는 오차를 제곱 후 모두 더해 평균을 내는 방식으로 오차를 산출합니다.
특징
- 오차를 제곱하므로 값이 클 수록 민감하게 반응합니다. 반대로 1 미만의 값은 더욱 둔감하게 반응합니다.
- 연속적이고 미분 가능한 함수입니다.
단점
- 오차 값이 클수록 민감하게 반응하므로 이상치에 큰 영향을 받습니다.
평균 제곱근 오차 (RMSE, Root Mean Square Error)
\[\text{RMSE} = \sqrt{\frac{1}{N} \sum_{i = 1}^{n} (\hat{y_i} - y_i)^2}\]- \(n\): 데이터 수
- \(y_i\): 실제 값
- \(\hat{y_i}\): 예측 값
- \((\hat{y_i} - y_i)^2\): 오차의 제곱
RMSE는 MSE에 제곱근을 씌우는 방식으로 오차를 산출합니다.
특징
- 오차 제곱에 루트를 씌우므로 MSE에 비해 왜곡이 줄어듭니다.
- 실제 오류 단위와 유사하게 표현하므로 오차를 직관적으로 표현할 수 있습니다.
단점
- MSE와 마찬가지로 스케일에 의존적입니다.
분류 오차함수 종류
이번에는 분류 학습에 사용하는 오차함수에 대해 알아보겠습니다. 분류 학습에 사용되는 오차함수는 엔트로피라는 개념이 사용됩니다. 그래서 먼저 엔트로피(entropy)의 개념에 대해 간략하게 설명하고 진행하겠습니다.
엔트로피 (Entropy)
엔트로피란 불확싱성을 측정하는 척도입니다. 수식으로 표현하면 다음과 같습니다.
\[H(X) = - \sum_{i = 1}^{n} P(x_i) \log_2 P(x_i)\]- \(X\): 확률변수 (예: 주사위 던지기 결과)
- \(x_i\): 확률변수 \(X\)가 가질 수 있는 값
- \(P(x_i)\): \(x_i\)가 발생할 확률
사건이 일어날 확률과 log2를 적용한 확률을 곱한 귀 모두 더해 부호를 반전시킨 값이 엔트로피 값 입니다.
의미
엔트로피는 확률 분포의 불확실성을 나타내는 지표입니다. 값이 가지는 의미는 다음과 같습니다.
- 엔트로피가 낮음: 사건의 불확실성이 작다는 의미입니다. 특정 사건이 발생할 확률이 0.99인 동전던지기가 있다면, 이 동전던지기의 엔트로피는 낮습니다.
- 엔트로피가 높음: 사건의 불확실성이 크다는 의미입니다. 모든 경우의 수가 \(\frac{1}{6}\)으로 같은 주사위 던지기가 있다면, 이 주사위던지기의 엔트로피는 높습니다.
특성
- 엔트로피 값은 항상 0 이상입니다. 어떠한 사건이 발상할 확률이 1 이라면, 엔트로피는 0 입니다.
- 엔트로피가 최대가 되는 경우는 모든 사건이 발생할 확률이 완벽히 같을 때 입니다.
대략적인 엔트로피의 개념에 대해 설명했습니다. 이제 엔트로피를 이용한 오차함수에 대해 설명하겠습니다.
교차 엔트로피 (Cross Entropy)
Croess Entropy는 이름 그대로 두 확률분포의 엔트로피를 측정하는 함수입니다. 수식으로 표현하면 다음과 같습니다.
\[H(P,Q) = - \sum_{i=1}^{n} P(x_i) \log_2 (Q(x_i))\]- \(P(x_i)\): 실제 값이 \(x\)일 확률
- \(Q(x_i)\): 예측 값이 \(x\)일 확률
식을 보면 알 수 있듯이, cross entropy는 실제 깂과 예측 값이 얼마나 같은지 엔트로피로 수치화 하여 표현합니다. 두 값이 완전히 동일하면 엔트로피는 0에 수렴합니다. 반대로 차이가 클 수록 엔트로피는 커지겠죠. 이를 활용해서 라벨 예측의 정확도를 판단하게 됩니다.
이진 교차 엔트로피 (BCE, Binary Cross Entropy)
이름 그대로 이진분류에 활용하는 오차함수입니다. 참고로 이진 분류란 분류할 라벨이 2개인 경우입니다. 식으로 표현하면 다음과 같습니다.
\[\text{BCE} = - \frac{1}{N} \sum_{i=1}^{n} (y_i \log (\hat{y_i}) + (1 - y_i) \log (1 - \hat{y_i}))\]- \(n\): 데이터 수
- \(y_i\): 실제 값
- \(\hat{y_i}\): 예측 값
식을 보면 라벨의 실제 값에따라 앞 또는 뒤 식이 0이 곱해져 사라진다는 사실을 알 수 있습니다.
특징
- 라벨을 0과 1로 표현하는 이진 분류에서 사용하는 손실함수 입니다.
- 실제 라벨값이 0 이라면 \((1 - y_i) \log (1 - \hat{y_i})\)을 이용해 오차를 계산하고, 실제 라벨값이 1 이라면 \(y_i \log (\hat{y_i})\)을 이용해 오차를 계산합니다.
- 예측 값은 0 또는 1일 확률로 예측됩니다. 0에 가까울수록 라벨이 0일 확률이 높다고 판단하고, 그 반대는 1일 확률이 높다고 판단합니다.
범주형 교차 엔트로피 (CCE, Categorical Cross Entropy)
분류해야 할 라벨 개수가 3개 이상일때 활용하는 오차함수 입니다. 각 카테고리는 원핫 인코딩(One Hot encoding)되어 표현됩니다.
원핫 인코딩(One Hot Encoding) 이란?
CCE 설명 전 원핫 인코딩에 대해 설명하고 넘어가겠습니다.
원학 인코딩은 여러개의 라벨을 0과 1로만 표현된 배열로 변경하는 작업입니다.
예를들 0, 1, 2라는 라벨이 있을떄, 원핫 인코딩을 하면 다음과 같이 변환됩니다.
- 0 -> [1, 0, 0]
- 1 -> [0, 1, 0]
- 2 -> [0, 0, 1]
이렇게 라벨 개수만큼의 0으로 채워진 배열을 만들고, 각 라벨에 해당하는 idx를 1로 변경해서 라벨 값을 표현합니다.
그럼 왜 굳이 라벨을 숫자로 표현하지 않고 원핫 인코딩 해서 표현할까요? 이유는 수치 관계 왜곡 방지에 있습니다. 단순히 라벨을 0, 1, 2로 표현하면, 모델을 각 라벨을 0 < 1 < 2와 같이 수치 관계로 해석할 수 있습니다. 하지만 라벨을 이러한 수치 관계가 없으므로 라벨을 모두 동일하게 0과 1로만 표현해 줍니다.
그러면 이제 CCE에 대해 자세히 알아봅시다. CCE를 식으로 표현하면 다음과 같습니다.
\[\text{CCE} = - \frac{1}{N} \sum_{i=1}^{n} \sum_{j=1}^{j} (y_{ij} \log (\hat{y_{ij}}) + (1 - y_{ij}) \log (1 - \hat{y_{ij}}))\]- \(n\): 데이터 수
- \(j\): 원핫 인코딩 인덱스 개수
- \(y_{ij}\): i번째 데이터의 j번째 원핫 인코딩 실제 값
- \(\hat{y_{ij}}\): i번째 데이터의 j번째 원핫 인코딩 예측 값
생긴건 BCE랑 거의 똑같습니다. 달라진 점은 원핫 인코딩이 적용된 라벨이 들어오기 때문에 한 데이터당 원핫 인코딩 개수 만큼 차이를 연산 후 더하는 작업이 추가되었다는 것 입니다. 하지만 원리 자체는 같기떄문에 이해하는데 큰 어려움은 없을겁니다.
이렇게 가장 ML을 배운다면 가장 먼저 배우는 오차험수에 대해 자세히 알아봤습니다. 오차함수는 이 외에도 Focal Loss, Reconstruction Loss, Connectionist Temporal Classification Loss, Adversarial Loss 등 학습 형태와 데이터 특성에 따라 다양한 오차함수가 존재합니다. 상황에 따라 그때그때 필요한 오차함수를 찾아서 사용하면 됩니다. 나중에 제가 필요하다면 여러 오차함수에 대해 더 자세히 정리해 보겠습니다.