
개요
원래는 Transformer 다음 글은 BERT에 대해 연재하려고 했는데, 친구의 요청으로 LoRA 먼저 작성하게 되었습니다.
LoRA (Low-Rank Adaptation of Large Language Models)는 점점 커져가는 LLM을 효율적으로 파인튜닝하기 위한 방법입니다.
요즘 LLM은 적게는 300M(Million, 백만), 많게는 수백B(Billion, 10억)개의 파라미터를 가집니다.
그래서 VRAM이 80GB인 몇천만원짜리 A100이 수십수백대가 있어야 효율적으로 학습이 가능합니다.
하지만 저와같은 학생들이나 중소규모의 회사는 이런 인프라 따위는 없습니다.
LoRA는 저희같은 사람들에게는 매우 유용한 파인튜닝 방법입니다.
LoRA
LoRA는 Low-Rank Adaptation의 줄임말로, 모델을 파인 튜닝(Fine-Tuning) 할때 모델 전체 파라미터를 업데이트 하는것이 아닌, Low-Rank 행렬을 추가하여 기존보다 훨씬 적은 파라미터를 업데이트 하여 파인튜닝하는 기법입니다. LoRA는 모델의 weight를 freeze 한 뒤에 추가한 Low-Rank 행렬만 학습하기 때문에 학습에 소요되는 자원과 시간 모두 Fully Fine-Tuning보다 훨씬 적습니다.
학습 방법
기존 파인 튜닝은 모델의 weight를 직접적으로 최적화 하는 방식입니다.
수식으로 표현하면 다음과 같습니다.
- \(W_0\): pre-trained weight
- \(\Delta W\): weight의 변화
이때 \(\Delta W\)는 \(W_0\)와 동일한 크기입니다. 이는 메모리 사용량이 높아지는 원인이 됩니다.
LoRA는 파인 튜닝 과정에서 달라지는 weight의 변화량 \(\Delta W\)만 학습합니다. 이때 \(\Delta W\)를 decompose (factorize) 해서 \(A\)와 \(B\) 행렬의 곱으로 분해해 크기를 줄입니다. 수식으로 표현하면 다음과 같습니다.
\[\Delta W = AB, W_0 + \Delta W = W_0 + BA\]이때 \(W_0\)는 freeze하고, weight의 변화량을 분해한 \(B\)와 \(A\) 행렬만 업데이트 합니다.
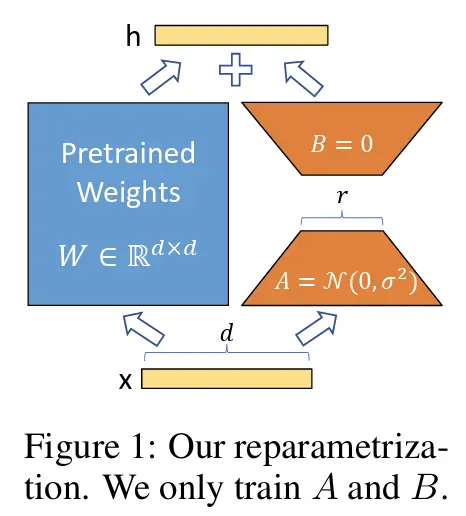 출처: https://arxiv.org/pdf/2106.09685
출처: https://arxiv.org/pdf/2106.09685
위 그림은 LoRA 논문에 소개된 LoRA 적용 과정입니다. 왼쪽에 파란색 부분은 기존에 학습된 pretrained Weight으로, dxd의 크기를 가지고 있습니다. LoRA 파인튜닝 시에는 freeze되어 업데이트 되지 않습니다.
오른쪽에 두 주황색은 weight의 변화량을 행렬 분해한 \(A\)와 \(B\) 행렬로, 각각 LoRA_A, LoRA_B 라고 합니다. 두 행렬 모두 단순한 Linear로 구성되며, LoRA_A는 dxr, LoRA_B는 rxd 크기를 가집니다. 이때 r은 사용자가 설정한 낮은 차원 숫자 입니다.
어떤 데이터 x가 들어와 모델을 파인튜닝 하고싶을 때, 기존 weight는 freeze 후 x를 통과시켜 기존 결과 값을 얻고, LoRA 레이어에 같은 x값을 통과시켜 변화에 대한 결과값을 얻은 후 합하여 새로운 결과 h를 만듭니다. 수식으로 표현하면 \(h = W_0 x + (BA)x\) 입니다.
적용 및 효과
LoRA는 모델의 어느 부분에 적용하는지에 따라 효과가 달라집니다. 논문에서 진행한 몇가지 테스트를 보도록 하겠습니다.
GLUE benchmark 데이터셋을 이용한 RoBERTa, DeBERTa 실험 결과
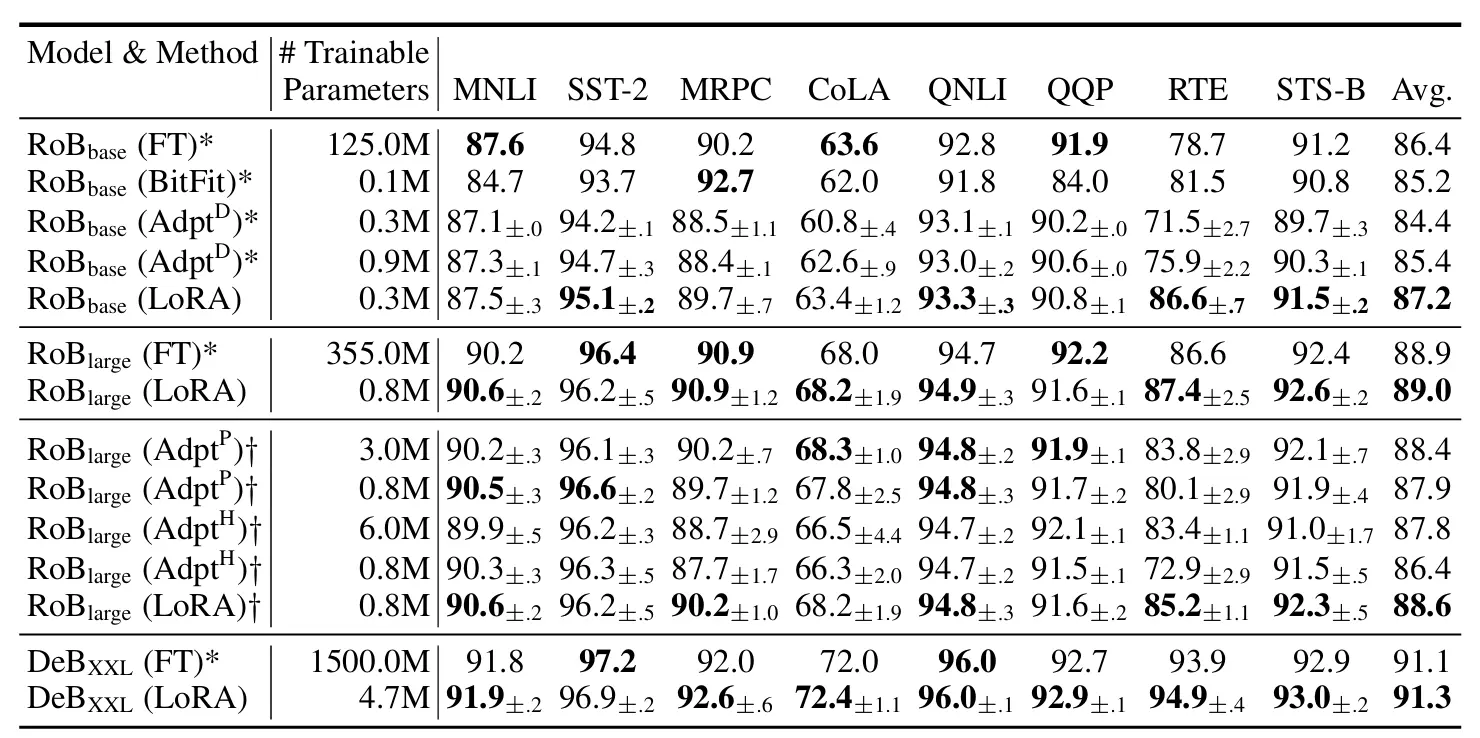 출처: https://arxiv.org/pdf/2106.09685
출처: https://arxiv.org/pdf/2106.09685
실험 결과를 보면 LoRA는 기존 방식보다 Trainable Parameter의 개수가 약 400배 적지만, 성능은 비슷하거나 더 높습니다. 이는 적은 파라미터로 학습 과정이 안정적으로 진행되었기 때문입니다.
GPT2, GPT3 실험 결과
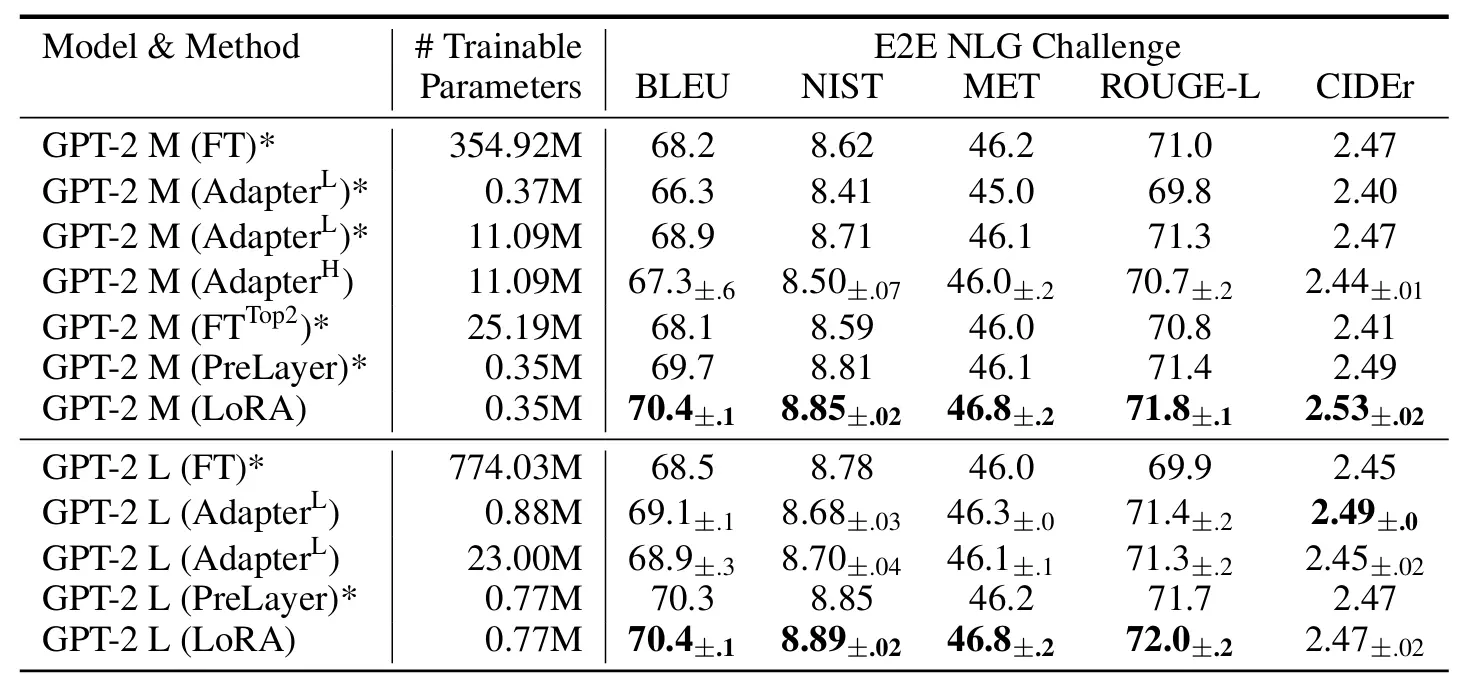 출처: https://arxiv.org/pdf/2106.09685
출처: https://arxiv.org/pdf/2106.09685
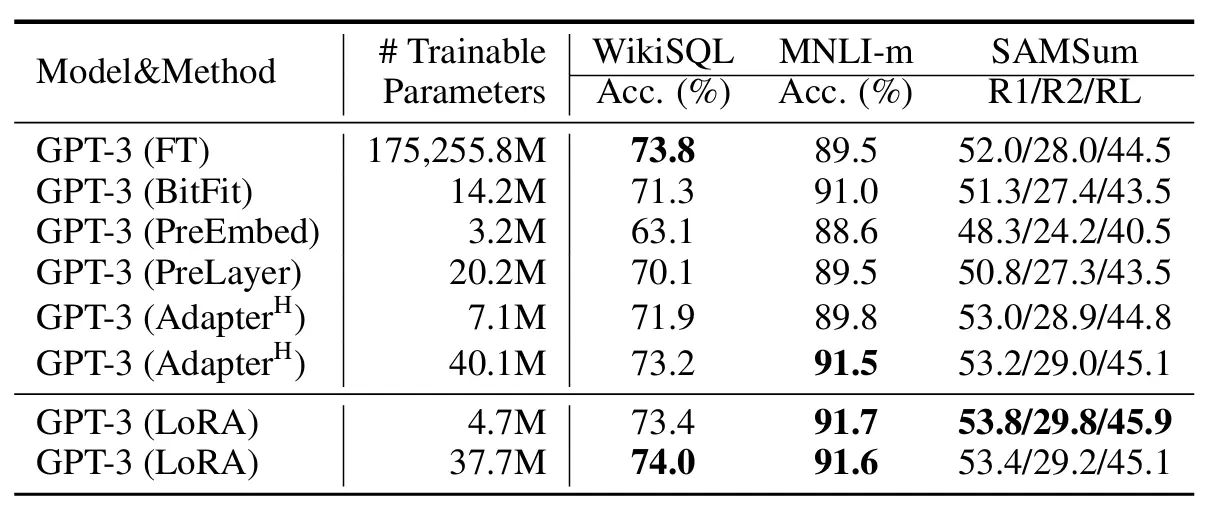 출처: https://arxiv.org/pdf/2106.09685
출처: https://arxiv.org/pdf/2106.09685
LoRA가 기존 방식보다 Trainable Parameter 개수가 적개는 약 100배, 많게는 약 4700배 차이나지만, 성능은 비슷하거나 오히려 높다는 사실을 알 수 있습니다. 여기서 알 수 있는 점은, LoRA는 모델의 파라미터가 많을수록 효율적이라는 점 입니다.
Transformer 실험 결과
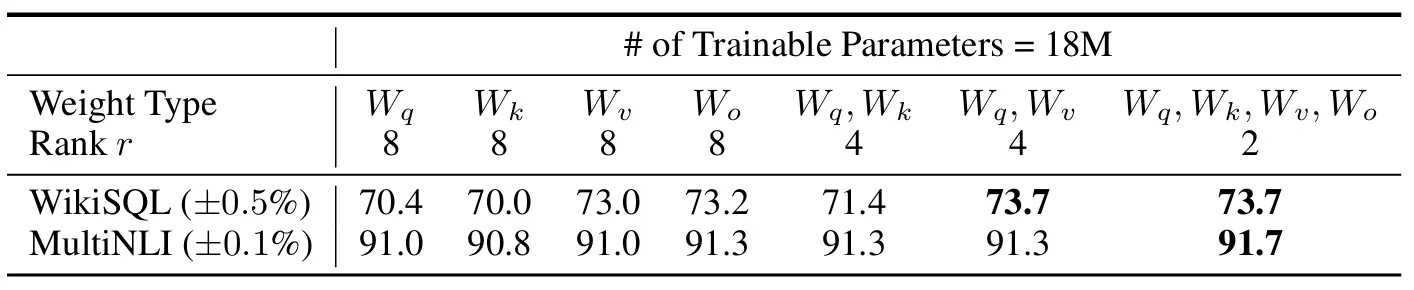 출처: https://arxiv.org/pdf/2106.09685
출처: https://arxiv.org/pdf/2106.09685
이 실험은 Transformer의 Q, K, V, Output 중 어디에 LoRA를 적용해야 효율적인지 확인하기 위해 진행한 실험입니다. 실험 결과 여러 부분에 적용하는게 가장 성능이 좋았다고 합니다.
LoRA는 현재 다양한 분야에서 활용되고 있습니다. 대표적으로 그림 생성 AI에서 다양한 그림채를 LoRA로 여러 버전 학습시킨 후, 생성 모델에 특정 그림체가 학습된 LoRA를 적용하여 적은 파일 용량으로 다양한 그림체를 활용하고 공유하는데 사용됩니다.
LoRA 전에도 다양한 PEFT(Parameter-Efficient Fine-Tuning) 기법이 연구되고 발표되었었지만, 현재는 LoRA가 가장 보편적으로 사용되는 PEFT 기법입니다. LoRA 기법을 사용하고 싶다면 직접 구현할 필요 없이, PEFT 라이브러리를 사용하면 됩니다.
다음 글을 예정대로 BERT에 대해 작성하겠습니다.