
개요
얼마전에 로깅시스템을 변경했습니다. 기존에는 ELK(Elasticsearch, Logstash, Kibana)를 사용했었는데, 현재는 PLG(Promtail, Loki, Grafana)로 변경했습니다. PLG 스택이 뭔지, 바꾼 이유와 ELK와 비교해서 어떤지 적어보고자 합니다.
PLG Stack?
ELK 스택은 들어봤어도 PLG 스택은 생소하실수도 있습니다. PLG는 ELK처럼 사용되는 기술들의 맨 앞글자를 하나씩 따서 이어붙인겁니다. 각각 Promtail, Loki, Grafana를 뜻합니다.
Promtail
Promtail은 Grafana가 개발한 로그 수집기입니다. Promtail은 정기적으로 모니터링 대상 로그를 수집하고, 파싱하여 태그를 붙여 Loki에게 전달합니다. ELK의 Logstash에 대응됩니다.
Loki
Promtail에게 전달받은 로그를 저장하는 저장소 역할입니다. Elasticsearch와 다르게 전체 텍스트를 인덱싱 하지않고, 지정한 레이블만 인덱싱한다는 특징이 있습니다. 그래서 Elasticsearch에 비해 매우 가볍습니다.
Grafana
Loki에 저장된 로그를 이용해서 여러 지표를 볼 수 있게 해주는 인터페이스입니다. Loki에게 LogQL로 로그를 검색하고 응답 속도, 최근 로그 등 로그를 시각화 합니다. ELK의 Kibana에 대응됩니다.
그래서 왜 바꿨나?
PLG를 보면 결국 하는 역할은 ELK와 다를바가 없어보입니다. 그러나 ELK와 PLG는 자원 사용량에서 큰 차이가 납니다.
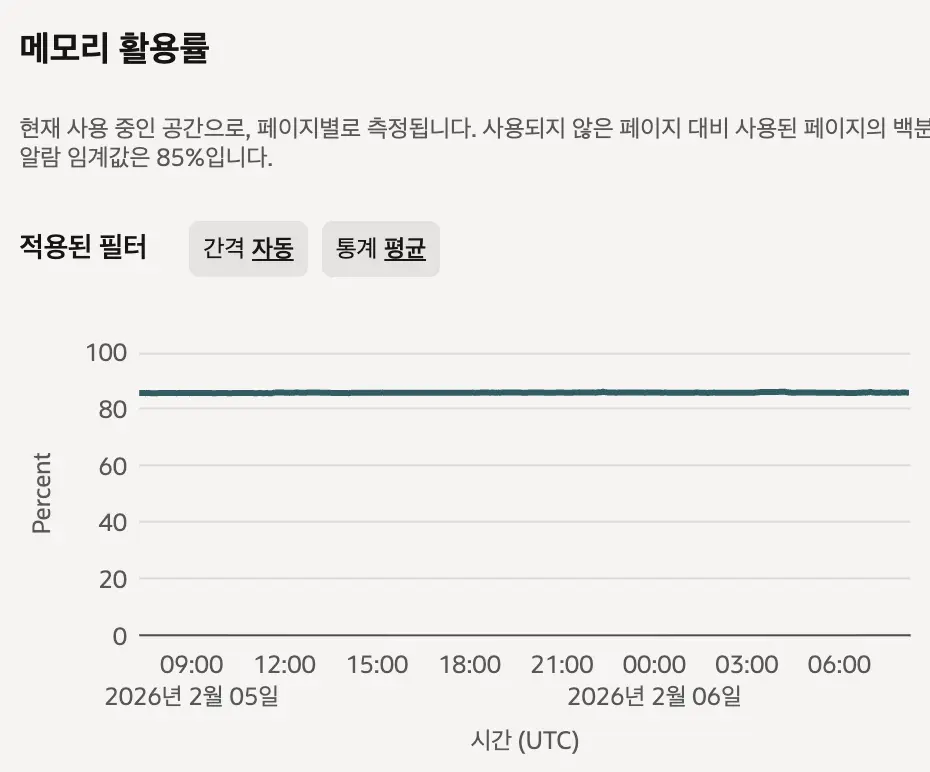
위 사진은 ELK 로깅시스템이 올라가있는 인스턴스의 램 사용량입니다. 인스턴스의 램이 12GB니까 무려 약 9.6기가를 사용중인겁니다. 램을 이렇게 많이 소모하는 이유는 Elasticsearch의 역색인 때문입니다. 역색인은 Full-text search를 위해 특정 키워드와 문서 위치를 기록해두는 기술입니다. Elasticsearch는 빠른 검색을 위해 역색인을 램에 일부 저장해두는데, 단어가 많으면 램을 더 많이 소모하게됩니다.
그러나 제가 로그를 보면서 Elasticsearch의 역색인을 활용할 일이 잘 없다고 느꼈습니다. 대부분 로그를 분석할땐 기간 단위로 잘라서 보는데, 특정 키워드를 검색해서 찾을 일이 잘 없었기때문입니다. 그래서 Elasticsearch를 비싼 자원을 사용하면서 쓸 이유가 없다고 생각했고, 찾아낸 대안이 Loki였습니다.
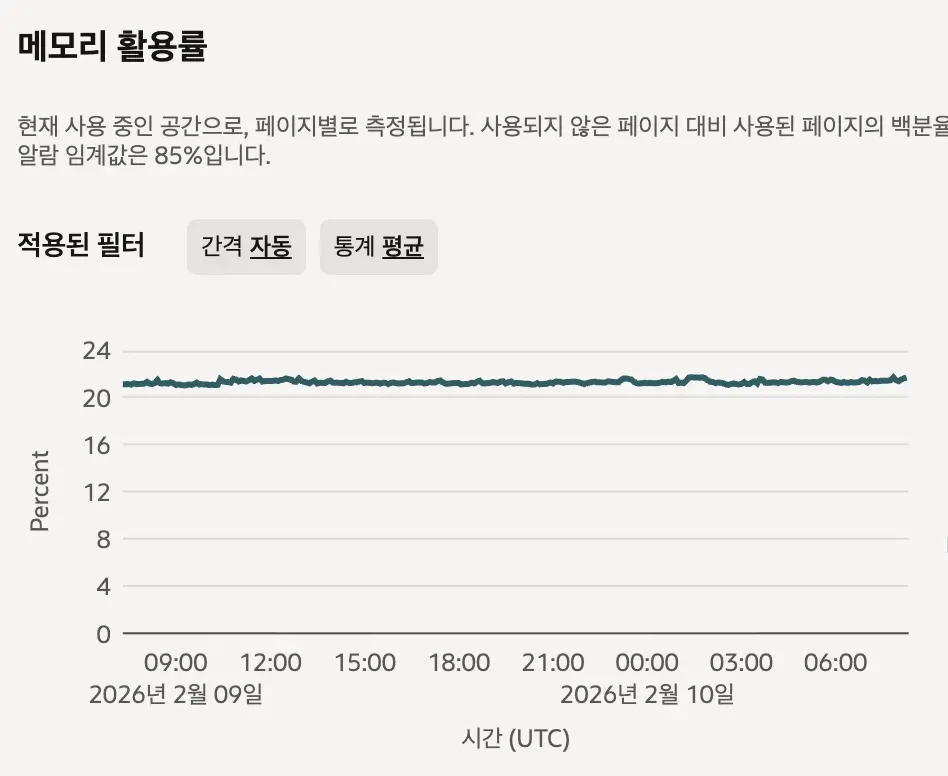
이건 동일한 인스턴스에 PLG 스택을 올린 뒤 캡쳐한 램 사용량입니다. 20%니까 약 2.5기가 정도 소모하고 있는겁니다. ELK에 비해 무려 74%나 감수한 수치입니다. 그래서 인스턴스의 램을 5GB로 줄여서 클라우드 비용 지출까지 줄일 수 있었습니다.
이게 가능한 이유는 Loki는 색인을 로그 전체가 아닌 레이블만 하기 때문입니다. 덕분에 Loki는 Elasticsearch에 비해 훨씬 적은 자원으로 동작이 가능합니다.
물론 Elasticsearch처럼 빠르게 Full-text search를 하지는 못하지만, 경험상 어차피 별로 안쓰는 기능이라 크게 상관은 없는것 같습니다.
구체적인 구성
이번에는 실제로 어떤식으로 구축이 되었는지 상세히 설명해보려고 합니다.
로그 형식
로그는 일반적인 텍스트가 아닌 json 형식으로 구성되어 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"level": "INFO",
"request_id": "a5d7fe0b-964b-4979-a2bd-762db2904822",
"message": "Response: POST http://127.0.0.1:8000/api/v1/auth/logout | Status: 200 | Time: 82.94ms",
"logger": "app_logger",
"time": "2026-02-10 19:46:34.826753",
"module": "logging",
"pathname": "/path_name/logging.py",
"filename": "logging.py",
"funcName": "logout",
"lineno": 18,
"env": null
}
로그를 일반적인 텍스트가 아닌 json 형식으로 찍는 이유는 Promtail에서 로그를 파싱할때 json이면 더 쉽게 가능하기 때문입니다.
각 요청에는 고유한 request_id를 만들어서 여러 요청이 섞일때는 request_id를 이용해서 필터링 할 수 있게 했습니다.
Promtail
1
2
3
4
5
6
7
8
9
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /var/lib/promtail/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
server는 Promtail의 상태를 모니터링하기 위한 설정입니다. 9080포트를 통해 수집 현황을 볼 수 있습니다.
positions는 Promtail이 어디까지 로그를 읽었는지 기록해두는 파일의 경로입니다.
clients는 promtail이 어디로 로그를 보낼지 정의하는 부분입니다. 저는 docker compose를 이용했기 때문에 loki 컨테이너의 이름을 경로로 설정했습니다.
1
2
3
4
5
6
7
scrape_configs:
- job_name: test-log
static_configs:
- targets: [localhost]
labels:
job: test-log
__path__: /var/log/test-log/*.log
로그를 어디서 가져올지 설정하는 부분입니다.
__path__는 수집할 로그의 위치를 지정하는 부분인데, 저는 test-log 내부에 모든 로그를 수집하게 했습니다.
이 위치의 labels는 정적 라벨 설정으로, test-log라는 job에서 수집되는 모든 로그는 job: test-log라는 라벨을 갖게 설정했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
pipeline_stages:
- json:
expressions:
log_time: time
log_level: level
filename: filename
funcName: funcName
- labels:
log_level:
- timestamp:
source: log_time
format: "2006-01-02 15:04:05.000000"
가져온 로그를 어떻게 가공할지 설정하는 부분입니다.
여기서 로그를 json으로 출력하는 이유가 나오는데, Promtail에서 json 설정을 주면 알아서 json 형식으로 역직렬화 해서 로그를 파싱합니다.
expressions에서 라벨로 사용할 필드를 추출하고, labels에서 색인할 필드를 지정합니다. 이때 카디널리티가 높은 값을 사용하면 너무 많은 색인 생성으로 성능이 저하될 수 있어서 저는 log_level만 지정했습니다.
timestamp는 로그가 찍힌 시간을 지정하는 부분인데, 로그 자체에 찍힌 시간을 활용하게 했습니다. 이부분을 지정하지 않으면 실제로 로그가 찍힌 시간이 아닌 Loki에 저장된 시각이 찍혀서 로그 순서가 달라질 수 있습니다.
Loki
1
2
3
4
5
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
Loki에 대해 기본적인 설정을 하는 부분입니다.
auth_enabled는 멀티테넌시를 설정하는 부분입니다. Loki는 자체적인 인증 기능이 없기때문에, X-Scope-OrgID라는 헤더를 통해 접근 가능한 로그를 제어합니다. 이 기능을 활성화 할지 설정하는 부분인데, 저는 저 혼자 사용하는거라서 비활성화 했습니다.
server는 다른 서비스가 Loki에 접근하기 위한 포트를 설정하는 부분입니다.
1
2
3
4
5
6
7
8
9
10
11
common:
instance_addr: 127.0.0.1
path_prefix: /loki
storage:
filesystem:
chunks_directory: /loki/chunks
rules_directory: /loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
이부분은 공통 설정을 정의하는 부분입니다. Loki는 내부적으로 Distributor, Ingester, Qurier 등 다양한 마이크로서비스로 구성되어 있습니다. 그래서 각 서비스들에게 공통으로 설정해야하는 부분을 여기에 정의합니다.
instance_addr은 Loki가 위치한 곳이 어디인지 표시하는 설정입니다. 쿠버네티스나 도커 환경에서 여러 서비스에 각각 Loki가 존재할 때에는 각 Loki를 구분하기 위해 실제 주소를 써야하지만, 저는 단일로 사용하기 때문에 localhost로 지정했습니다.
그 아래는 Loki 데이터가 저장될 장소를 지정하는 부분입니다.
replication_factor는 로그를 몇개를 복제해서 저장할지 지정하는 부분인데, 아직까지 로그를 그정도로 저장해야할 필요성을 느끼지 못해서 일단 단일로 설정했습니다.
ring은 분산 환경에서 어느 노드에 저장할지 결정하기 위한 Hash Ring(해시링)과 관련된 설정입니다. 저는 단일노드이기 때문에 메모리에만 저장하게 설정했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: s3
schema: v13
index:
prefix: index_
period: 24h
storage_config:
tsdb_shipper:
active_index_directory: /loki/tsdb-index
cache_location: /loki/tsdb-cache
cache_ttl: 24h
aws:
region: {object storage region}
s3: {object storage url}
access_key_id: {secret key}
secret_access_key: {secret key}
s3forcepathstyle: true
insecure: false
이부분은 로그 데이터를 어떻게 인덱싱하고 저장할지 결정하는 부분입니다. 설정을 요약하자면, 처음 로그와 인덱스 정보가 들어오면 TSDB에 저장해두고, 일정 시간이 지나면 Object Storage에 업로드 한다는 뜻 입니다.
처음 Loki에게 로그와 인덱스가 전달되면 active_index_directory에 인덱스가 작성되고, 로그는 Chunk 단위로 압축되어 저장됩니다. 그러다가 설정된 period가 지나면, Object Storage에 업로드 하여 데이터를 외부에 저장합니다. 이는 인스턴스가 유실되더라도 데이터를 남겨 보존하기 위함입니다. 그리고 업로드된 캐시는 바로 지우지 않고 cache_ttl만큼 로컬에 남겨 접슨 속도를 높입니다.
아래 aws는 Object Storage 설정인데, 저는 Oracle Cloud를 사용중인데도 S3 호환 API를 활용해서 문제없이 구축이 가능했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
ingester:
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 1h
max_chunk_age: 1h
chunk_target_size: 1536000
chunk_encoding: snappy
wal:
enabled: true
dir: /loki/wal
이부분은 로그를 수집하는 수집기를 설정하는 부분입니다. 설정 자체는 common과 거의 동일하나, Chunk에 관한 설정이 더 있습니다.
위 설정은 1시간동안 아무런 로그가 들어오지 않을때, 1시간이 지날때, 1시간이 지나지 않아도 지정된 크기를 넘기면 무조건 Chunk로 만들어 저장소에 저장한다는 설정입니다.
그리고 wal 설정을 통해 들어온 로그를 메모리 뿐만 아니라 디스크에도 저장해서 복구가 가능하게 만들었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
compactor:
working_directory: /loki/boltdb-shipper-compactor
delete_request_store: s3
compaction_interval: 10m
retention_enabled: true
retention_delete_delay: 2h
retention_delete_worker_count: 150
limits_config:
retention_period: 1440h
reject_old_samples: true
reject_old_samples_max_age: 168h
max_entries_limit_per_query: 5000
이부분은 로그의 관리 방법을 정의하는 부분입니다. 로그를 무한정 저장할 수 없기때문에 로그를 보관할 기간, 로그를 받아들일 기간드을 설정합니다.
저는 retention_period을 1440시간(60일)로 설정해 뒀습니다. 그리고 168시간(7일)이 지난 로그는 받지 않도록 해서 불필요한 저장을 방지했습니다.
Grafana
1
2
3
4
5
6
7
8
9
10
11
12
datasources:
- name: Loki
type: loki
uid: loki-uid-01
access: proxy
url: http://loki:3100
isDefault: true
editable: true
jsonData:
maxLines: 2000
timeout: 60
Grafana에서 어떤 데이터를 어디서 받을지 설정하는 부분입니다. Grafana에서 Loki라는 이름으로 Loki에서 데이터를 가져오게 하는 설정입니다.
대시보드 구성
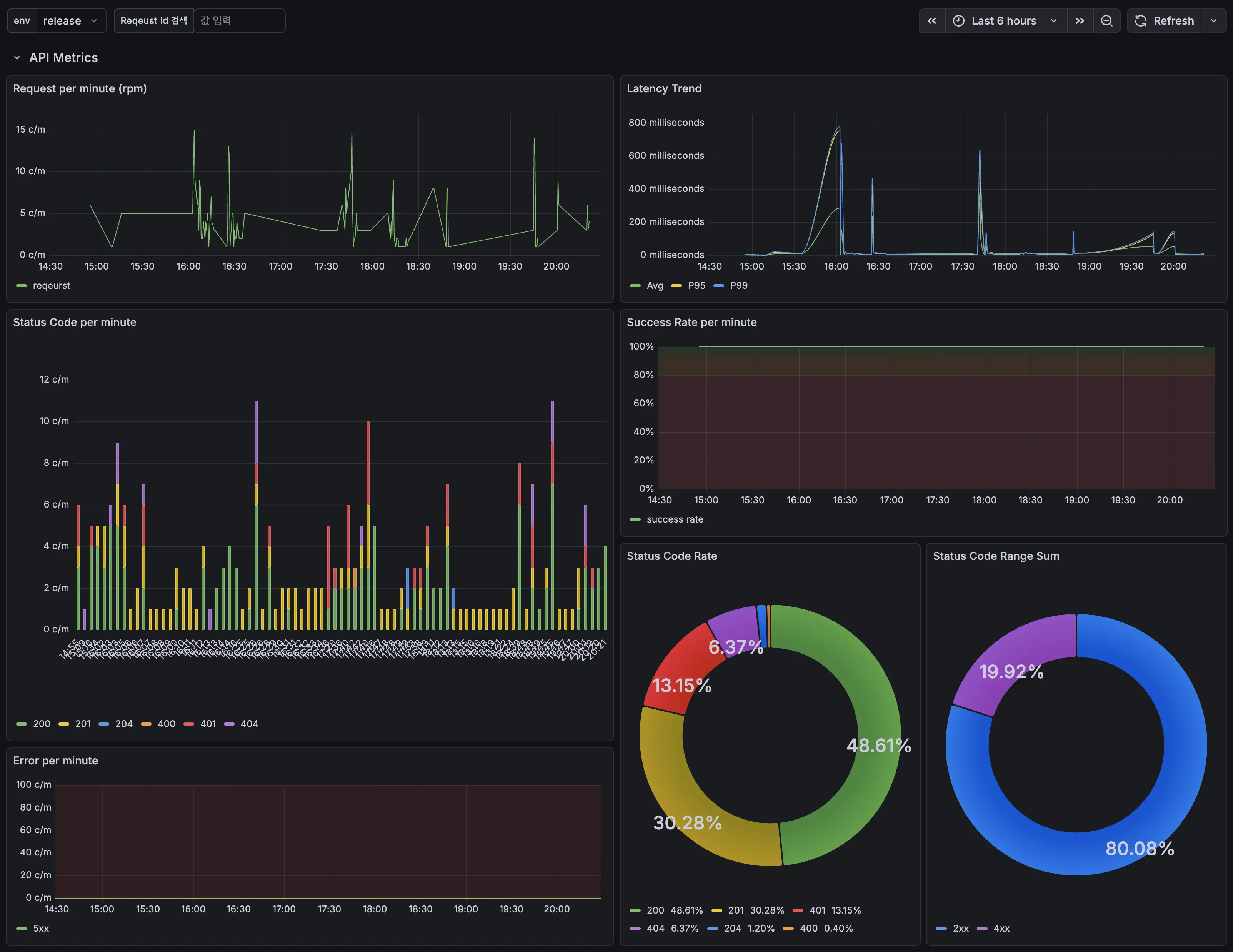
최종적으로 완성된 대시보드 입니다. 분당 요청 횟수, 평균/99%/95% 레이턴시, 분당 응답 코드, 분당 응답 성공/실패율, 응답 코드 비율을 보여줍니다. 아래에는 나오지는 않았지만 로그를 목록으로 보여줍니다.
이제 로그를 더 효율적으로 수집하고, 다양하게 분석해 볼 수 있는 발판이 만들어졌습니다. 다음 글은 DB에 대한 글 입니다.
앱 다운받기