
개요
인프라를 개선하면서 같이 구축한 모니터링 시스템을 이용해서 현재 인프라가 어느정도 버틸 수 있는지 테스트 해봤습니다. 테스트 과정과 병목을 찾아 해결한 과정까지 적어보겠습니다.
Locust
부하 테스트를 위해 사용한 툴은 Loucst 입니다. 직역하자면 메뚜기인데, 메뚜기 떼 처럼 달려들어서 서버를 공격해서 이런 이름이 붙여졌나 봅니다. Locust는 파이썬으로 스크립트를 작성할 수 있기때문에 선택하게 되었습니다.
Locust는 가상의 유저를 만들어서 특정 api를 반복적으로 실행하거나, 시퀀셜하게 특정 api를 순서대로 실행하는걸 반복하게 만들 수 있습니다. 테스트가 진행되는동안 자체적인 웹 ui를 통해 응답 시간, 에러율과 같은 지표도 볼 수 있습니다.
테스트 계획
본격적인 테스트 스크립트 작성에 앞서 어떤 기능을 통해 부하 테스트를 해볼지 정해야 했습니다.

그래서 사람들이 가장 많이 사용하는 기능이 뭔지 GA4로 분석을 해봤는데, 수시 데이터 추가/수정이 이벤트 발생 상위 3,4위를 차지하는것을 알게되었습니다. 실제로 학기중에 사용자들의 이용 패턴을 보다보면 성적을 추가하고 수정하는 이벤트가 압도적으로 많은데, 사용자들이 성적을 단순히 기록하지 않고 예상해 보기 위해서 입력과 수정을 반복하는 것으로 파악하고 있습니다. 그래서 여담이지만 관련 기능도 한번 추가해 보려고 합니다.
아무튼 가장 많이 사용하는 기능인 수시 데이터 추가/수정 그리고 삭제까지 추가해서 순서대로 반복적으로 api를 요청하는 부하 테스트를 진행하기로 결정했습니다.
테스트 계정 발급 API 추가
그런데 테스트를 진행하기 앞서 문제가 하나 있었습니다. 수시 데이터 편집과 관련된 API는 DPop인증이 필요한 API라서 테스트를 진행하려면 최소 한번은 DPop 로그인 과정이 필요했습니다. 문제는 하이스코어는 현재 Oauth를 통한 로그인만 지원하기 때문에 기존 로그인 프로세스를 따라가면 구글계정이 수백개가 필요하다는 문제가 있습니다.
그래서 이 문제를 해결하기 위해 테스트용 임시 계정을 만들어 발급하는 API를 추가로 만들었습니다. 테스트 전 원하는 테스트 사용자 수를 입력하면 개수만큼 테스트 계정을 만들어 uid, access/refresh token, device id를 리스트로 제공하게 만들었습니다.
테스트가 마무리되면 테스트 계정은 모두 쓸모없어지기 때문에 테스트 계정을 모두 삭제하는 API도 추가했습니다.
혹시나 모를 보안문제 방지하기
만들고보니 아무리 테스트 계정이라지만 제3자가 10만개, 1억개 이런식으로 넣어 요청하면 문제가 생길것 같았습니다. 그래서 몇가지 조치를 추가했습니다.
1
2
3
4
5
router = APIRouter()
if settings.FASTAPI_ENV != 'RELEASE':
router.include_router(test.router, prefix='/test')
print(f"[주의] 테스트용 API가 활성화되었습니다. (현재 환경: {settings.FASTAPI_ENV})")
우선 fastapi에 url 등록을 releas 환경에서는 막아 보여지지 않게 만들었습니다. 테스트 환경에서는 아예 테스트와 관련된 API를 띄우지 않는게 맞다고 생각이 되어 추가한 조치입니다.
두 번째 조치는 테스트 API 요청시 최소한 어드민 계정을 가지고 있는 사람만 호출이 가능하게 만들었습니다. 각 API 요청마다 어드민 계정을 요구하게 만들면 DPop 인증 특성상 그때마다 DPop-Proof키를 새로 만들어야되서 테스트용 인증키를 발급하고 테스트 요청시 인증키를 포함시키는 방식으로 구현했습니다.
흐름을 정리해보자면 어드민 레벨의 사용자가 테스트에 사용할 임시키 발급 -> 테스트 사용자 생성 -> 테스트 진행 -> 계정 폐기 순서로 진행이 됩니다.
테스트 스크립트 작성
이제 테스트 스크립트를 작성할 차례입니다. 우선 테스트를 진행 전후 반드시 진행해야하는 사항을 먼저 작성해 보겠습니다.
테스트 유저 생성
1
2
3
4
5
6
7
@events.test_start.add_listener
def on_test_start(environment, **kwargs):
...
@events.test_stop.add_listener
def on_test_stop(environment, **kwargs):
...
Locust는 events.test_start.add_listener와 events.test_stop.add_listener로 테스트 전후 실행할 전처리와 후처리를 작성할 수 있습니다. on_test_start에는 관리자 로그인 및 DPop 생성, 테스트키 요청, 임시계정 생성 및 큐에 저장, 어드민 계정 로그아웃 순서로 구현했습니다. on_test_stop은 임시 계정을 삭제를 요청하는 기능만 구현해뒀습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from queue import Queue, Empty
TEST_CONTEXT = {
"admin_access_token": None,
"admin_key_info": None,
"admin_dpop_nonce": None,
"test_key": None,
"test_users_queue": Queue()
}
...
@events.test_start.add_listener
def on_test_start(environment, **kwargs):
...
try:
...
url_gen = f"{host}/api/v1/test/account"
gen_body = {
"count": environment.runner.target_user_count,
"jwk": TEST_CONTEXT["admin_key_info"]["public_jwk"],
"name": "Locust-Test-User",
"platform": "Locust"
}
headers = {
"x-key": TEST_CONTEXT["test_key"]
}
resp = requests.post(url_gen, json=gen_body, headers=headers)
resp.raise_for_status()
users_list = resp.json()
for u in users_list:
TEST_CONTEXT["test_users_queue"].put(u)
Locust에서 제공하는 environment.runner.target_user_count 변수를 이용해서 Locust에서 지정한 테스트 유저 수를 그대로 사용하게 만들었고, DPop인증에 사용하는 비대칭키는 유저마다 관리하는건 자원 낭비라고 판단되어 하나로 통일하게 만들었습니다.
사용자 목록은 리스트가 아니라 큐로 만들었는데, idx로 하나씩 가져오기보다는 Queue에서 하나씩 pop 해서 사용하는게 더 편리하다고 판단해서 큐로 저장하게 만들었습니다.
가상 사용자 구성하기
Locust는 HttpUser을 상속받아 가상의 유저를 정의할 수 있습니다. HttpUser을 상속받아 만든 클래스에 유저들이 필수로 가져야 하는 기능을 정의했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class SchoolCalUser(HttpUser):
wait_time = between(1, 5)
def on_start(self):
try:
self.user_data = TEST_CONTEXT["test_users_queue"].get(block=False)
self.access_token = self.user_data["access_token"]
self.device_id = self.user_data["device_id"]
self.current_nonce = self.user_data.get("nonce")
self.key_info = TEST_CONTEXT.get("admin_key_info")
except Empty:
self.user_data = None
def on_stop(self):
if self.user_data:
self.user_data["nonce"] = self.current_nonce
TEST_CONTEXT["test_users_queue"].put(self.user_data)
def _update_nonce(self, response):
...
def dpop_request(self, method, path, headers=None, **kwargs):
if headers is None:
headers = {}
...
url = f"{self.host}{path}"
...
response = self.client.request(method, path, headers=headers, **kwargs)
self._update_nonce(response)
return response
on_start는 테스트에 가상유저가 참여하기 시작할때 실행되는 함수로, 큐에서 가상 유저를 꺼낸 후 기본 정보를 설정하는 부분입니다. on_stop은 테스트에 가상유저가 참여를 마치면 실행되는 함수로, 큐에서 꺼낸 유저를 다시 넣어두는 기능을 만들었습니다.
dpop_request는 DPop인증이 필요한 API를 위해 만들어진 함수인데, DPop은 매 요청마다 Proof키를 만들고 이전 응답에서 받은 nonce값을 저장했다가 활용해야 합니다. 관련 기능들을 함수화 해서 request 기능을 간편하게 사용 가능하도록 만들었습니다.
맨 위에있는 wait_time은 실제 유저처럼 각 요청을 1~5초의 랜덤한 간격을 두고 실행하게 설정하는 부분입니다.
테스트 시나리오 작성
이제 실제 테스트 시나리오를 작성할 차례입니다. 수시 데이터 추가/수정/삭제를 순차적으로 실행해야 하므로 SequentialTaskSet를 상속받아 시나리오를 작성했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class SusiSequence(SequentialTaskSet):
API_SUSI = '/api/v1/susi'
TEST_ID = str(ObjectId())
@task
def add_susi_data(self):
data = {
'id': self.TEST_ID,
'name': 'test',
'grade': 1,
'unit': 1,
'type': 0
}
url = f'{self.API_SUSI}?semester=21&doc_version=jkdlas9kjksnjd'
self.user.dpop_request('POST', url, headers={
'Content-Type': 'application/json'
}, json=data)
@task
def edit_susi_data(self):
data = {
'semester': '21',
'name': 'test222222',
'grade': 2,
'unit': 3,
'type': 1
}
url = f'{self.API_SUSI}/21/{self.TEST_ID}?doc_version=dsaddsa22'
self.user.dpop_request('PATCH', url, headers={
'Content-Type': 'application/json'
}, json=data)
@task
def delete_susi_data(self):
url = f'{self.API_SUSI}/21/{self.TEST_ID}?doc_version=dsf3das3d'
self.user.dpop_request('DELETE', url)
class SusiScenarioTest(SchoolCalUser):
tasks = [SusiSequence]
@task 데코레이터를 이용해 이 함수가 수행할 테스크라는걸 알려주고, SequentialTaskSet은 위에서부터 아래로 순서대로 실행하게 됩니다. 작성된 테스크는 SchoolCalUser를 상속받은 클래스에 tasks 변수에 지정해서 가상 유저가 수행해야할 테스크로 연결해 줍니다.
이제 테스트 실행을 위한 스크립트 작성이 끝났습니다. 실제로 테스트를 진행해 보겠습니다.
테스트1. 동시에 500명 규모
일단 500명이 동시에 수시 추가/수정/삭제를 반복한다고 가정하고 첫 테스트를 진행했습니다. 테스트 기록은 이전에 구축한 모니터링 시스템으로 실시간으로 기록했습니다.
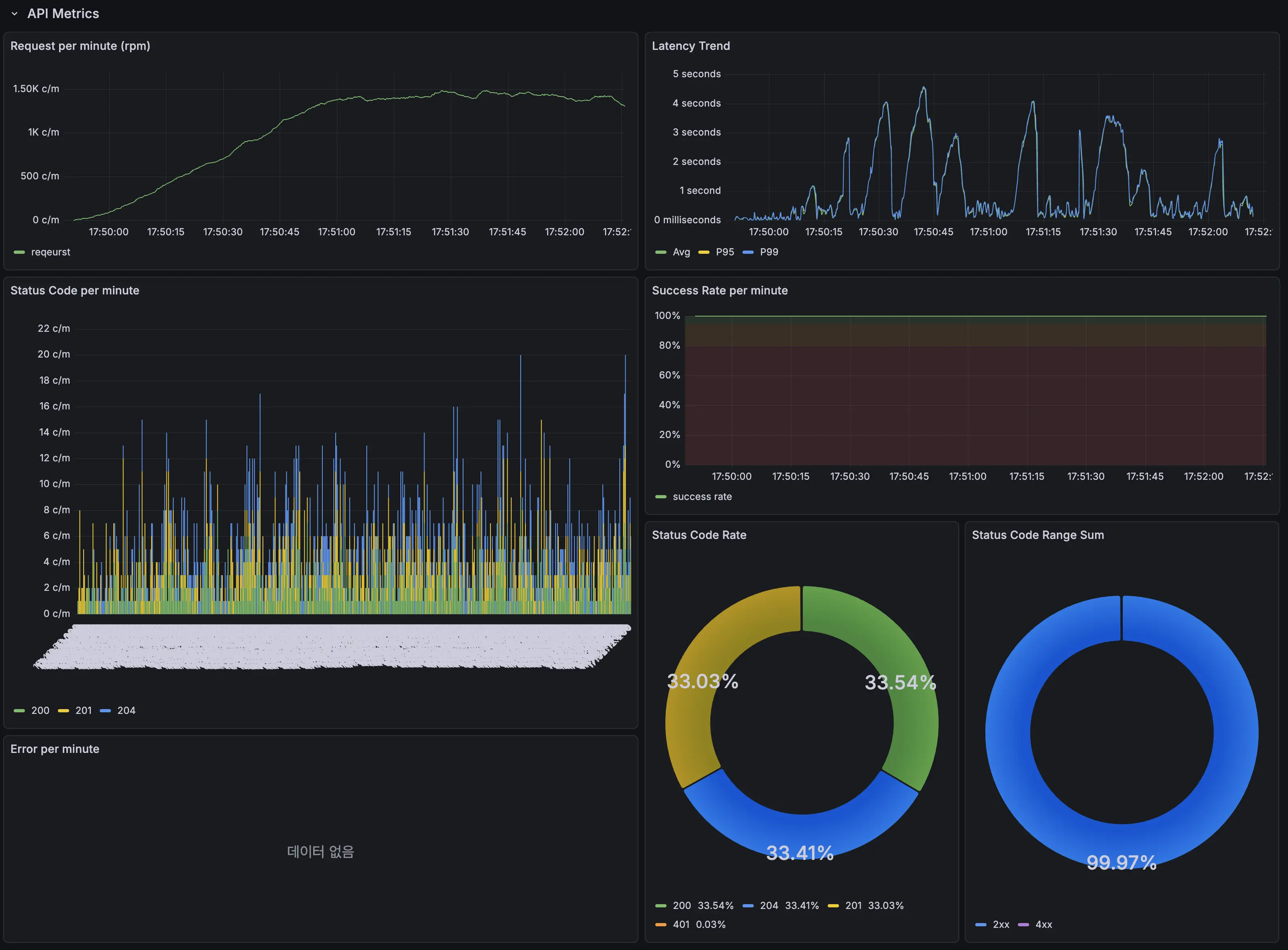
그런데 테스트를 30초 정도 지속하기 갑자기 응답속도가 최대 4.5초까지 튀는 문제가 발생했습니다. 이 현상이 한번이 아니라 테스트 도중 지속적으로 발생했습니다.
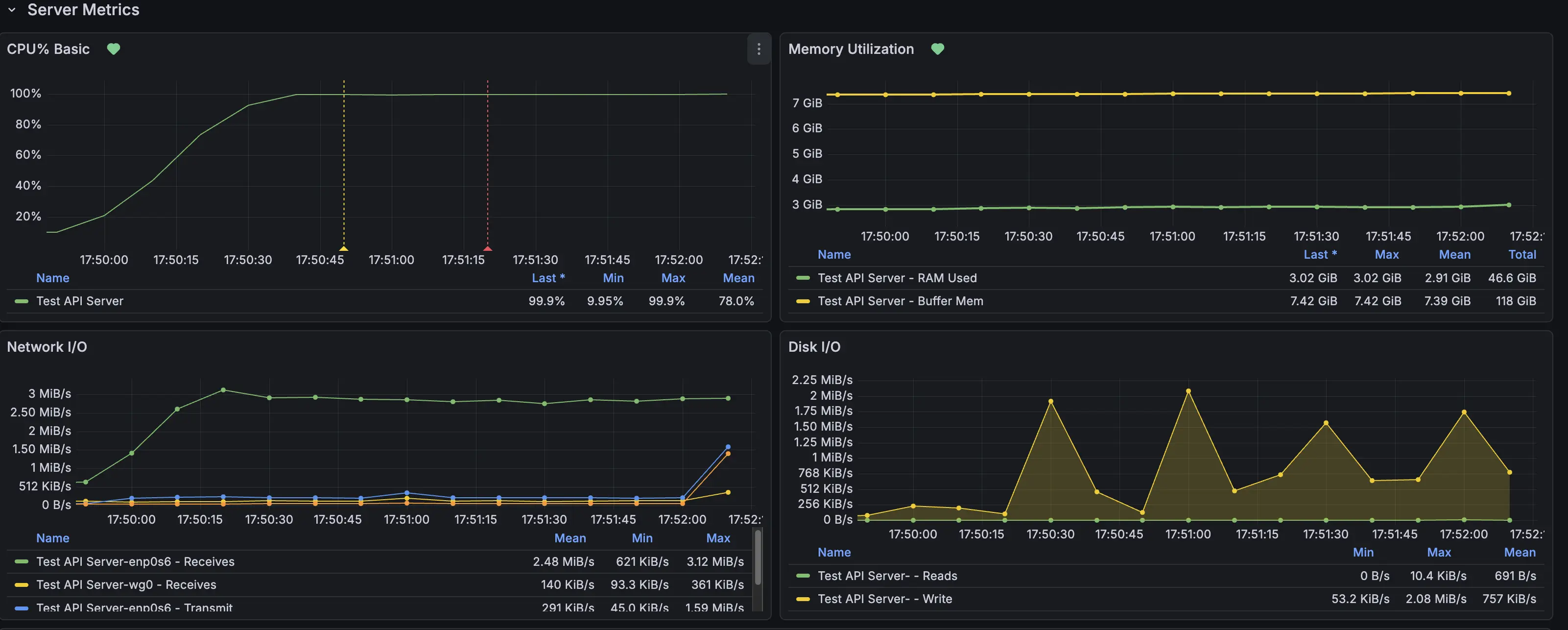
원인은 바로 API 인스턴스의 CPU 사용량 때문이었습니다. CPU 사용량이 100%를 찍으면서 응답을 처리하는데 지연이 발생했고, 레이턴시가 급격히 늘어나게 된 것 입니다.
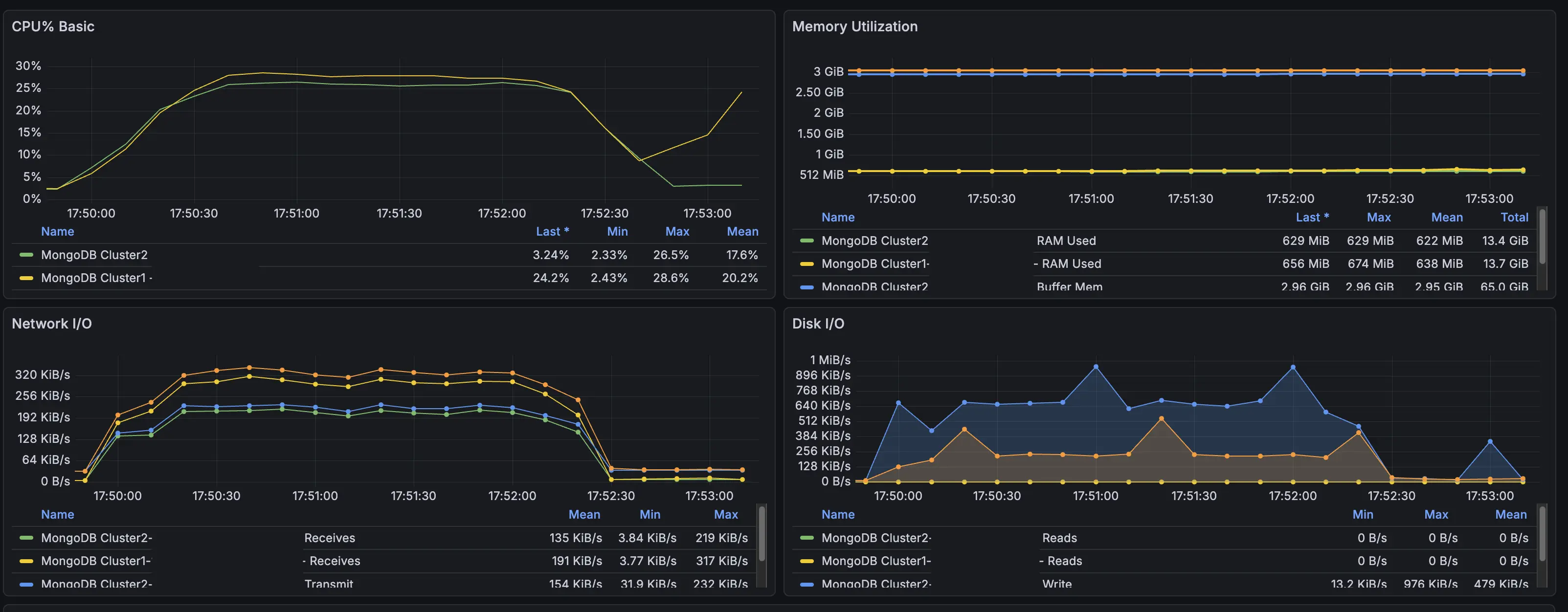
그런데 MongoDB가 올라가있는 인스턴스들은 CPU 사용률이 최대 30%까지만 오르는 것을 확인하고, 이번 문제의 원인은 api 구현에 병목을 일으키는 원인이 있다고 판단하여 코드를 살펴봤습니다.
병목 분석
첫 번째 테스트에서 얻은 결과를 바탕으로 수시 성적 추가/수정/삭제 코드에 어떤 부분이 병목을 일으키는지 찾아보게 되었습니다. 우선 기존 코드의 일부를 보고 문제점을 짚어보겠습니다.
파일을 읽고 수정하여 덮어쓰기
1
2
3
4
5
6
7
8
user_data = await collection_susi_grade.find_one({"uid": uid})
...
if user_data:
... # 파이썬에서 데이터 추가
await collection_susi_grade.update_one({"uid": uid}, {"$set": update_doc})
else:
...
await collection_susi_grade.insert_one(new_data)
기존 코드는 모두 사용자 uid를 이용해 추가할 사용자의 수시 정보를 가져온 후, 파이썬에서 직접 항목 추가/수정/삭제를 진행 후 덮어쓰기 하는 방식으로 구현되어 있었습니다. 한눈에봐도 굉장히 비효율적인데, 이런 구조에서 발생할 수 있는 문제점을 정리하자면 다음과 같습니다.
우선 매번 전체 데이터를 파이썬 코드로 가져오면서 수행되는 직렬화/역직렬화의 반복이 CPU에게 부담을 줍니다. 동시 요청 사용자수가 적을때는 괜찮지만, 방금과 같이 수백명이 동시에 요청하게되면 문제가 발생하게 됩니다.
그리고 전체 데이터를 주고 받으면서 불필요한 데이터 교환이 반복됩니다. 매 요청마다 전체 데이터를 주고받으니 수정될 데이터만 보내는것 보다 훨씬 큰 데이터들이 교환되게 됩니다.
게다가 매번 $set으로 데이터를 덮어씌우니 디스크 읽기/쓰기도 쓸데없이 커지게 됩니다.
비효율적인 탐색
1
2
3
4
...
for idx, item in enumerate(grades):
if str(item["_id"]) == grade_id:
...
특정 데이터를 수정/삭제할때도 전체 데이터를 일단 가져오다보니 파이썬에서 직접 탐색을 진행하게 구현되었습니다. 이는 데이터가 적을땐 문제가 없지만, 많아지면 많아질수록 성능이 저하된다는 문제가 있습니다.
병목 해결하기
분석한 병목 원인을 바탕으로 하나씩 해결해 보겠습니다.
항목 추가
1
2
update_query = {"$push": {f"semesters.{semester}": {"$each": grades_dict}}}
await collection_susi_grade.update_one({"uid": uid}, update_query, upsert=True)
기존처럼 전체 데이터를 가져와 파이썬에서 직접 추가하는게 아니라 $push를 이용해 항목을 추가하게 했습니다. update_one에서 upsert를 활용해 데이터가 없다면 생성 후 추가하도록 했습니다.
데이터 수정
1
2
3
filter_query = {"uid": uid, f"semesters.{semester}._id": grade_id}
update_query = {"$set": {f"semesters.{semester}.$.{k}": v for k, v in update_data.items()}}
await collection_susi_grade.update_one(filter_query, update_query)
수정할 데이터를 파이썬에서 찾지 않고 MongoDB에서 직접 찾게 필터를 만들었습니다. 수정 대상을 찾으면 해당 데이터만 set 연산자로 덮어쓰도록 했습니다.
항목 삭제
1
2
update_query = {"$pull": {f"semesters.{semester}": {"_id": grade_id}}}
await collection_susi_grade.update_one({"uid": uid}, update_query)
pull 연산자를 활용해 조건에 맞는 항목을 배열에서 삭제하게 만들었습니다.
전체적으로는 MongoDB의 연산자를 활용해서 데이터를 수정하게 만든겁니다. 파이썬에서 전체 데이터를 가져와 직접 데이터를 탐색하고 덮어씌우는 방식보다 자원을 훨씬 덜 소모할 것으로 예상됩니다.
테스트2. 수정 전 후 비교
이번에는 병목 수정 전후를 동시에 350명이 추가/수정/삭제를 반복하는 규모로 테스트 후 비교해 보겠습니다. 같은 테스트를 실행한 후 Locust에서 제공하는 응답속도 테이블을 비교해 보겠습니다.
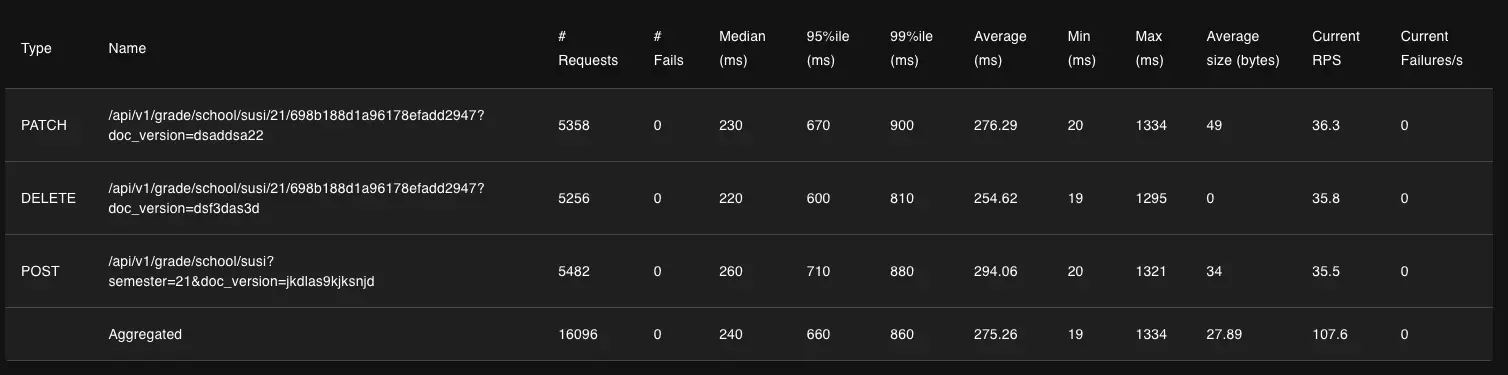
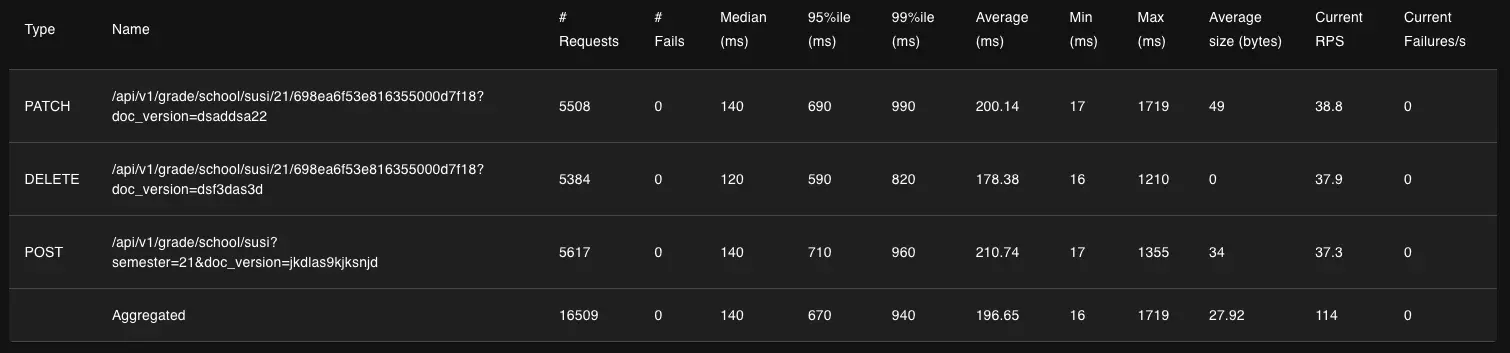
위에가 수정 전, 아래가 수정 후 입니다.
우선 응답속도의 중앙값을 비교해보면 추가 API는 260ms에서 140ms로 약 54%, 수정 API는 230ms에서 140ms로 약 39%, 삭제 API는 220ms에서 120ms로 약 45% 감소로, 모두 감소했음을 알 수 있습니다.
RPS(초당 요청 처리수)는 각각 35.5에서 37.3로 약 5%, 36.3에서 38.8로 약 7%, 35.8에서 37.9로 약 6% 상승으로, 모두 상승했을을 알 수 있습니다.
특이한게 응답속도 중앙값과 RPS는 모두 전보다 나아졌는데, P95와 P99는 수정 후에도 비슷하거나 오히려 더 느려졌습니다. 왜 이런 현상이 발생하는지 아직은 잘 모르겠지만, 우선 전체 처리량 자체는 늘어나서 수정한 버전을 반영해둔 상태입니다. 그렇지만 여기서 끝내지 않고 원인을 더 찾아볼 생각입니다.
서버 비용 아끼기
생각보다 API서버는 램을 많이 사용하지 않는다는 사실을 알게되었습니다. 그래서 기존에는 2코어 12GB를 서버로 사용했는데, 2코어 6GB로 줄이면서 월 서버 사용료를 감축할 수 있었습니다. 이번에 인프라를 바꾸면서 예상 월 비용이 5만원이었는데, 테스트 결과를 바탕으로 인스턴스 자원들을 재설정 한 결과 월 17000원으로 줄일 수 있었습니다.
테스트결과에 따르면 현재 인프라로도 동시에 200명 정도는 충분히 버틸 것 같습니다. 하이스코어는 중간/기말이 발표되는 피크에 DAU 300~400명을 기록하기 때문에 더욱 사용자들이 늘어나는게 아니면 일단은 지금 인프라를 쭉 유지할것 같습니다.
앱 다운받기