
BERT
BERT는 Transformer를 발표한 구글에서 발표한 자연어 모델입니다. Bidirectional Encoder Representations from Transformers의 약자로, Transformer의 Encoder 구조를 이용해서 양방향(Bidirectional)으로 문맥을 이해하는 모델입니다. 모델 이름에서 알 수 있듯이, 문장의 앞뒤 문맥을 모두 고려해서 단방향으로 문장을 읽어나가던 기존 모델보다 훨씬 더 좋은 성능을 보여줍니다.
구조
BERT는 이름에서 알 수 있듯이 Transformer의 Encoder 구조만 사용합니다. Transformer Encoder는 문맥을 파악하는데 특화되어 있고, Deocder는 문맥을 바탕으로 문장을 생성하는데 특화되어 있는데, BERT는 문맥 이해에 좋은 성능을 발휘합니다. 그래서 BERT는 문장 분류와 같이 문맥을 이해하고 판단하는데 특화되어 있습니다. 참고로 많은 대중들이 처음 접한 생성형 모델인 GPT는 Transformer의 Decoder 구조를 기반으로 만들어져 있습니다.
Embedding
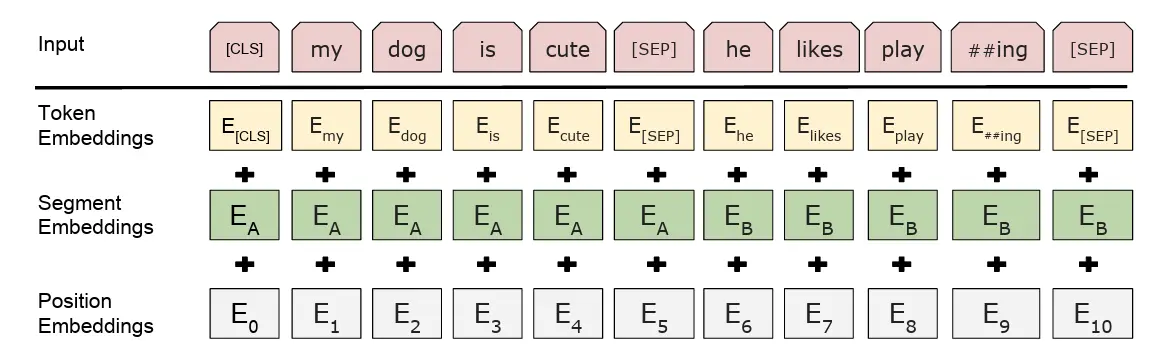 출처: https://arxiv.org/pdf/1810.04805
출처: https://arxiv.org/pdf/1810.04805
BERT는 세 개의 임베딩 레이어를 사용합니다.
Tokenization
임베딩이 수행되기 전, 문장을 토큰 단위로 분리하는 토크나이징이 먼저 수행됩니다. BERT는 토큰 단위로 쪼갤 때 WordPiece Tokenizer를 사용하는데, WordPiece는 단어를 Sub-Word로 쪼개서 딕셔너리에 없는 단어(OOV 단어)도 처리가 가능하다는 장점이 있습니다.
Sub-word 분리
기본적인 토크나이저는 문장에서 토큰을 분리할때 띄어쓰기 단위로 나눕니다.
‘I Love Coding’이라는 문장을 예시로 들면, 기존에는 I, Love, Coding으로 토큰이 나뉘었습니다.
WordPiece는 code라는 단어 외에도 ing와 같이 어떤 단어 뒤에 붙는 표현은 ##ing와 같은 형태로 나눕니다.
그래서 I, Love, Cod, ##ing와 같은 형태로 나뉘게 됩니다.
Special Token 추가
BERT는 문장의 시작 과 끝과 같이 문장 구조에 따라 특수한 토큰을 추가합니다.
대표적으로 문장 시작을 나타내는 [CLS], 끝을 나타내는 [SEP] 토큰이 있습니다.
최종적으로 I Love Coding은 [CLS], I, Love, Cod, ##ing, [SEP]로 토크나이징 됩니다.
Token Embedding
문장에서 변환된 토큰을 학습된 단어 백터로 바꾸는 레이어입니다. 단어 자체의 의미를 표현합니다.
Segment Embedding
BERT는 여러 문장을 동시에 입력할 수 있습니다. 그래서 특정 토큰이 어느 문장에 포함되는지 구분하는 백터를 Segment Embedding 레이어에서 추가합니다.
Position Embedding
BERT의 기반인 Transformer는 순서가 없어서 단어의 위치를 알 수 없습니다. 그래서 Position Embedding 레이어에서 단어의 위치 정보를 추가합니다.
Pre-traing
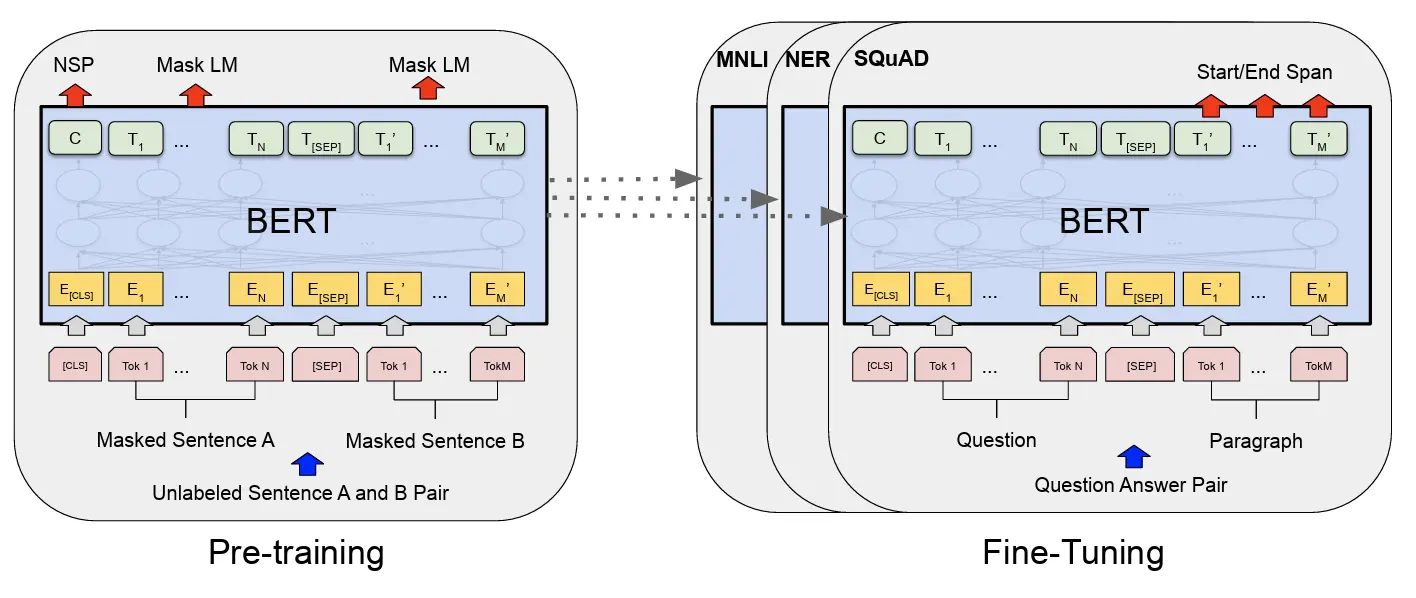 출처: https://arxiv.org/pdf/1810.04805
출처: https://arxiv.org/pdf/1810.04805
BERT는 지금은 일반적인 Pre-trainig과 Fine-tuning 방식을 적용한 모델입니다. BERT 학습시에는 위키피디아와 같은 방대한 양의 데이터를 이용해 언어의 문법, 문맥, 단어간 관계 등 문맥 파악에 필요한 정보를 대규모로 학습해두고(Pre-training), 세부 테스크를 재학습(Fine-tuning) 해서 성능을 끌어올립니다.
학습 방법
Pre-trainig 과정에서 모델을 두 가지 방법으로 학습을 진행합니다.
MLM (Maked Language Model)
MLM은 이름 그대로 특정 토큰을 가린 후(Mask), 앞뒤 문맥을 파악해서 마스크에 있는 단어가 무엇인지 맞추는 훈련입니다.
‘오늘은 날씨가 [MASK] 우산을 챙겼다.’ 라는 문장이 주어지면, 모델은 ‘흐려서’를 예측하는 방식입니다.
조금 더 구체적으로 살펴보자면, 마스킹은 입력된 문장의 15%만 무작위로 선별해서 진행합니다.
이때 마스킹 대상 단어 중 80%는 [MASK] 태그로 완전히 가리고, 10%는 다른 단어로 변경, 나머지 10%는 별다른 변환 없이 원본 단어를 유지합니다.
MLM은 문장의 앞뒤 문맥을 동시에 고려하는 문맥 파악 능력을 학습하는데 도움이 됩니다.
NSP (Next Sentence Prediction)
NSP는 두 문장을 주고, 이어지는 문장이 맞는지, 아니면 전혀 상관이 없는 문장인지 맞추는 훈련입니다.
‘남자가 가게에 갔다’ 라는 문장이 A 일때, B 문장이 ‘남자는 옷을 샀다’라면 이어지는 문장, B 문장이 ‘버스는 정류장에 멈추지 않았다’ 라면 이어지지 않는 문장으로 판단하는 방식입니다.
NSP는 문장과 문장 사이의 관계와 흐름을 파악하는 능력을 학습하는데 도움이 됩니다.
Fine-tuning
대규모 데이터셋으로 문장간 관계와 문맥 파악에 대해 Pre-trained 된 모델을 특정 테스크에 맞는 모델로 만드는 과정을 Fine-tuning이라고 합니다. 이 방식은 pre-training된 모델만 있으면 적은 자원으로도 뛰어난 성능의 모델을 만들 수 있다는 큰 장점이 있습니다. 그래서 현재 공개되는 LLM은 대부분 Pre-training된 모델들이 HuggingFace에 올라와 있고, 이 모델을 이용해서 목적에 맞게 Fine-tuning해서 사용합니다.
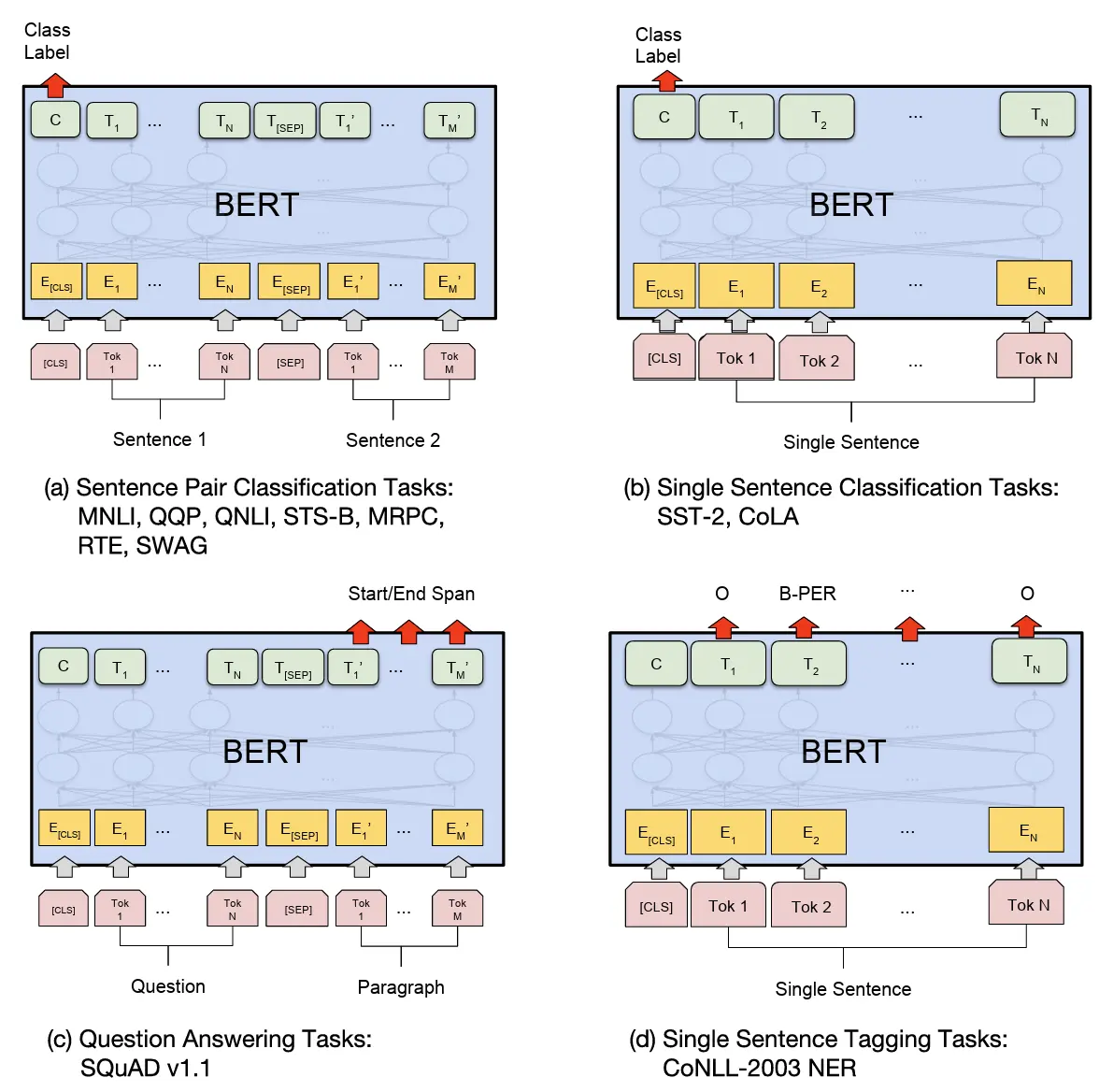 출처: https://arxiv.org/pdf/1810.04805
출처: https://arxiv.org/pdf/1810.04805
논문에서는 4가지 유형의 Fine-tuning을 제시합니다.
-
Single Sentence Classification (단일 문장 분류)
영화 리뷰 긍정/부정 분석과 같이 문장의 타입을 분류하는 테스크 -
Sentence Pair Classification (두 문장 관계 분류)
두 문장이 논리적으로 같은 뜻인지 판단하는 테스크 -
Question Answering (질의 응답)
질문과 지문을 주고, 지문 안에서 정답의 위치를 찾는 테스크 -
Single Sentence Tagging (토큰 태깅)
문장의 각 단어마다 품사, 개체명(인물, 장소)을 달아주는 테스크