
개요
딥러닝은 순전파(Forward Propagation)과 역전파(Back Propagation) 두 단계로 진행됩니다. 순전파는 입력 -> 신경망 -> 출력 순으로 계산해서 예측 값을 산출해내는 과정이고, 역전파는 출력 값으로 오차를 계산해서 신경망을 거슬러 올라가며 파라미터를 업데이트 하는 과정입니다. 각 과정에 대해 자세히 알아보겠습니다.
순전파(Forward Propagation)
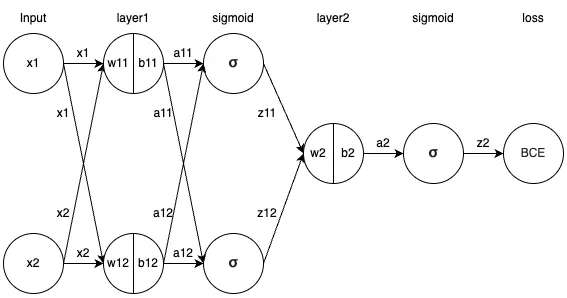
순전파는 데이터를 넣고 레이어를 거쳐 최종 예측값을 출력하여 오차를 계산하는 과정까지 포함됩니다.
계산 과정
위 이미지를 예를들어 계산 과정에 대해 설명드리겠습니다.
데이터가 input으로 들어오면 각 데이터는 각 노드에서 가중치와 바이어스를 곱하고 더해 계산되고, 활성화 함수를 거쳐 다음 레이어의 input으로 사용됩니다.
마지막으로는 BCE(Binary CrossEntropy) 오차함수를 이용해 실제 값과 예측 값의 오차를 구하게 됩니다.
수식으로 표현하면 다음과 같습니다.
1번 레이어
\(z_{11} = \sigma (x_{1} w_{11} + x_{2} w_{11} + b_{11})\)
\(z_{12} = \sigma (x_{1} w_{12} + x_{2} w_{12} + b_{12})\)
2번 레이어
\(z_{2} = \sigma (z_{11} w_{2} + z_{12} w_{2} + b_{2})\)
loss
\(L = BCE(z_{2}, y)\)
입력부터 출력, 오차까지 순차적으로 계산되어 내려오는것을 수식을 통해 확인할 수 있습니다.
역전파 (Back Propagation)
순전파에서 구한 오차로 모델의 가중치와 바이어스와 같은 파라미터를 업데이트 할 차례입니다. 이때 계산 과정은 오차에서부터 역으로 올라가면서 진행됩니다. 그래서 이 과정을 역전파 라고 합니다.
계산 과정
이 과정은 편미분을 통해 gradient를 구해서 업데이트 되는데, 이때 Chain rule에 의해 계산됩니다.
Chain rule
체인룰은 합성함수의 미분을 계산하는 방법입니다. 미분되는 과정이 일종의 체인처럼 엮인 모습과 비슷해서 붙은 이름입니다.
\(u = g(x), y = f(u),\) 와 같은 수식이 있을때, \(y\)를 \(x\)에 대해 미분할때 다음과 같은 관계가 성립합니다.
\[\frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx}\]이제 가중치 \(w_{2}\)를 업데이트 하는 과정에 대해 수식으로 설명드리겠습니다.
예제로 설명하는 과정은 앞서 optimizer 글에서 소개한 Gradient Descent를 이용한 방법입니다.
첫 번째로 기울기를 구하기 위해 \(\frac{\partial L}{\partial w_{2}}\)를 구해야 합니다.
순전파에서 \(w_{2}\)에서 \(L\)을 계산하는 과정은 다음과 같습니다.
\(z_{2} = \sigma (z_{11} w_{2} + z_{12} w_{2} + b_{2})\)
\(L = BCE(z_{2}, y)\)
두 식을 정리하면 합성함수가 된다는 사실을 알 수 있습니다. 그러므로 \(\frac{\partial L}{\partial w_{2}}\)은 chain rule에 의해 다음과 같이 변형이 가능합니다.
\[\frac{\partial L}{\partial w_{2}} = \frac{\partial L}{\partial z_{2}} \cdot \frac{\partial z_{2}}{\partial w_{2}}\]더 구체적인 수식은 다음과 같습니다.
\(\frac{\partial L}{\partial z_2}\) 계산
BCE를 풀어쓰면 다음과 같습니다.
\[L = BCE(z_2, y) = - \left[ y \cdot \log(z_2) + (1 - y) \cdot \log(1 - z_2) \right]\]\(\frac{\partial L}{\partial z_2}\)에 대해 풀어쓰면 다음과 같습니다.
\[\frac{\partial L}{\partial z_2} = \frac{\partial}{\partial z_2} \left( - \left[ y \cdot \log(z_2) + (1 - y) \cdot \log(1 - z_2) \right] \right) = \frac{z_2 - y}{z_2 (1 - z_2)}\]\(\frac{\partial z_2}{\partial w_2}\) 계산
시그모이드 수식과 미분식을 풀어쓰면 다음과 같습니다.
\[\sigma(x) = \frac{1}{1 + e^{-x}}, \sigma{\prime}(x) = \sigma(x) (1 - \sigma(x))\]\(\frac{\partial z_2}{\partial w_2}\)에 대해 풀어쓰면 다음과 같습니다.
\[\frac{\partial z_2}{\partial w_2} = \sigma{\prime}(z_{11} w_2 + z_{12} w_2 + b_2) \cdot \frac{\partial}{\partial w_2} (z_{11} w_2 + z_{12} w_2 + b_2)\]\(\sigma{\prime}(z_{11} w_2 + z_{12} w_2 + b_2)\)에 대해 풀어쓰면
\[\sigma{\prime}(z_{11} w_2 + z_{12} w_2 + b_2) = \sigma(z_2) (1 - \sigma(z_2))\]\(\frac{\partial}{\partial w_2} (z_{11} w_2 + z_{12} w_2 + b_2)\)에 대해 풀어쓰면
\[\frac{\partial}{\partial w_2} (z_{11} w_2 + z_{12} w_2 + b_2) = z_{11} + z_{12}\]최종적으로 다음과 같습니다.
\[\frac{\partial z_2}{\partial w_2} = \sigma(z_2) (1 - \sigma(z_2)) \cdot (z_{11} + z_{12})\]\(\frac{\partial L}{\partial w_2}\) 계산
최종적으로 \(\frac{\partial L}{\partial w_2}\)은 다음과 같습니다.
\[\frac{\partial L}{\partial w_2} = \left( \frac{z_2 - y}{z_2 (1 - z_2)} \right) \cdot \left( \sigma(z_2) (1 - \sigma(z_2)) \right) \cdot (z_{11} + z_{12})\]\(w_2\) 업데이트
위에서 구한 기울기를 이용해서 다음과 같이 업데이트 합니다.
\[w_2 = w_2 - \eta \cdot \frac{\partial L}{\partial w_2}\]\(\eta\)는 learning rate로, 구한 기울기를 얼마나 반영할지를 나타내는 파라미터입니다.
위와같이 계산 과정을 업데이트 해야하는 모든 파라미터에 반복적으로 진행됩니다. 여담이지만 계산 과정을 살펴보면 딥러닝 학습시 왜 GPU를 이용해서 병렬처리를 하는지 알 수 있는것 같습니다. 예제는 노드가 몇개 없어서 암산으로도 가능한 수준이지만, 요즘 유행하는 LLM(Large Language Model)은 업데이트 해야하는 파라미터가 몇십억 단위다 보니 학습에 정말 엄청난 연산이 필요합니다.