
개요
seq2seq 구조는 길이가 다른 입력과 출력을 학습시킬 수 있는 좋은 솔루션입니다. 그러나 여전히 순환신경망이 가지는 단점은 해결하지 못했죠. Attention은 seq2seq의 문제점을 보완하는 구조입니다. 현재 대부분의 생성형 모델에서 사용되는 trnasformer 구조의 기초적인 구조로, 다양한 최신 모델을 이해하기 위한 중요한 개념중 하나입니다. Attention에 대해서 자세히 알아보겠습니다.
Attention
Attention(주목)이라는 이름에서 알 수 있듯이, Attention 매커니증은 어떤 정보에 주목해야하는지 학습으로 정하는 매커니즘 입니다.
seq2seq의 문제점에 대해 다시한번 생각해 보겠습니다. seq2seq은 encoder를 거치고 난 후 나오는 context vector의 길이가 항상 고정입니다. 이는 입력 시퀀스의 길이가 짧든 길든 같습니다. 그래서 길이가 긴 시퀀스일수록 점점 정보를 담기 어려워집니다. 이를 컨텍스트 백터 병목이라고 합니다.
Attention은 context vector를 각 step마다 동적으로 생성해서 병목 문제를 해결합니다. 아래에서 자세히 설명하겠습니다.
구조
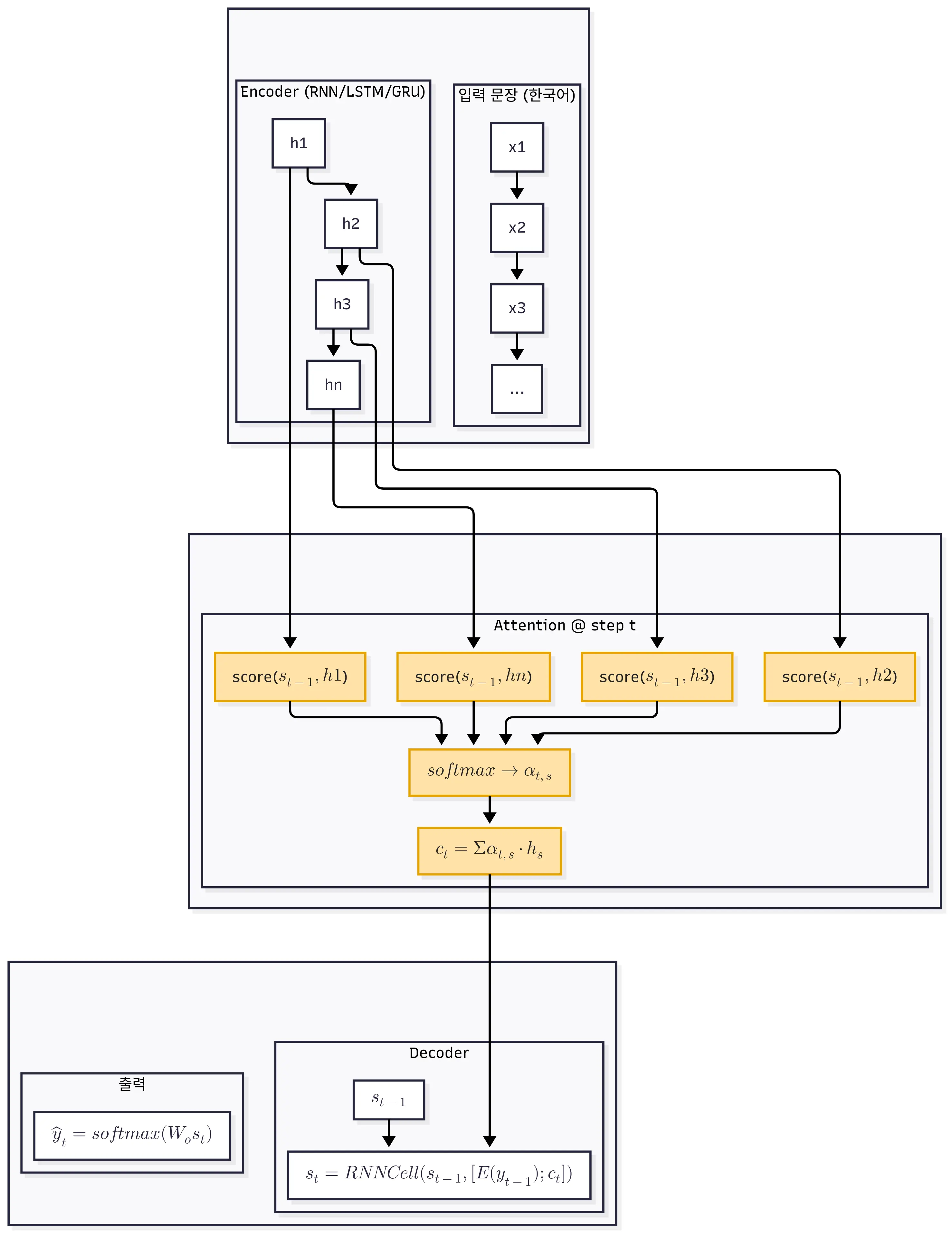
우선 전체적인 구조를 살펴보겠습니다.
encoder-decoder가 존재하는건 seq2seq와 비슷해 보입니다.
encoder는 seq2seq와 비슷하게 입력을 순차적으로 받아 hidden state를 만듭니다.
가장 큰 차이점은 context vector를 구성하는 부분입니다.
Attention은 context vector를 구성할 때, 각 step에서 어떤 시퀀스에 attetion 해야하는지 점수화 해서 context vector를 구성합니다.
Attention 동작 원리
Attention이 어떤 방식으로 작하는지 자세히 알아보겠습니다.
1. hidden state 계산
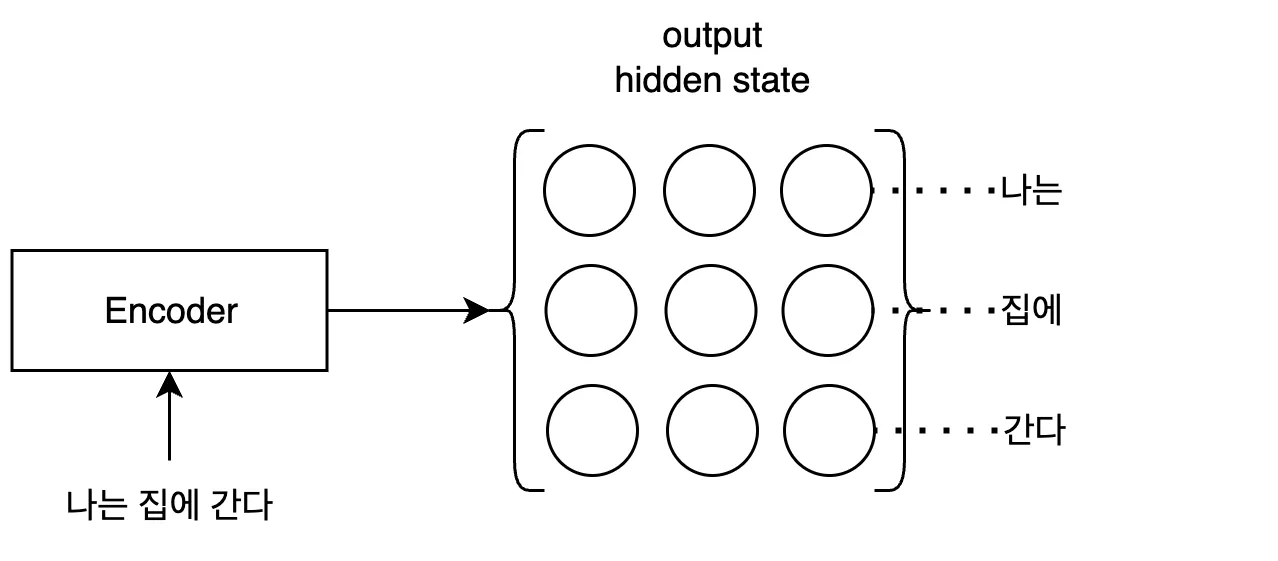
encoder는 모든 시퀀스의 데이터를 활용하기 위해 마지막 출력의 hidden state만 활용하지 않고, 모든 입력 시퀀스의 hidden state를 사용합니다. encoder의 모든 hidden state를 묶어 하나의 output hidden state를 만듭니다. 모든 시퀀스를 이용해 구성했기 때문에, 아무리 시퀀스가 길어져도 데이터 손실이 덜 일어납니다.
수식과 기호로 정리하면 다음과 같습니다.
- 인코더의 hidden state: \(H=\{h_1,\dots,h_S\}\), \(S\) = 입력 시퀀스 개수
2. Align Score 계산
decoder에서 이번 시퀀스를 생성할떄, output hidden state에서 어느 부분을 집중적으로 봐야하는지 score를 구하는 부분입니다. 이를 Align Score라고 하는데, 인코더의 hidden state의 위치와 생성하려는 데이터 간의 관계가 얼마나 잘 맞는지 점수화 한다고 이해할 수 있습니다. 이떄 score 계산 방법에는 Additive, Dot 등 여러 식이 존재합니다만, 이 글에서는 score 계산 식에 대한 설명은 생략하겠습니다.
수식과 기호로 정리하면 다음과 같습니다.
- 디코더의 직전 hidden state: \(s_{t-1}\)
- 시점 t에서 입력 위치 s에 대한 align score: \(e_{t,s}=\text{score}(s_{t-1},\,h_s)\)
수식을 보면 score를 구할 때 직전의 decoder hidden state가 들어가는걸 알 수 있습니다. 수식을 풀어서 설명하면, 직전에 생성된 시퀀스를 참고해서 이번에 생성할 시퀀스에게 중요한 부분을 계산해 낸다고 설명할 수 있습니다.
3. 정규화
위에서 구한 각 위치마다의 align score를 정규화합니다. 보통 sofmax를 이용해 모든 가중치의 합이 1이 되도록 조정합니다. 결과적으로 0~1 사이의 값으로 어떤 hidden state가 중요한지 표현하게 됩니다.
수식과 기호로 정리하면 다음과 같습니다.
- 시점 t에서 입력 위치 s에 대한 normalized align score: \(\alpha_{t,s}=\frac{\exp(\widetilde e_{t,s})}{\sum_{u=1}^{S}\exp(\widetilde e_{t,u})},\quad \sum_{s}\alpha_{t,s}=1\)
4. context vector 생성
정규화한 align score를 이용해 context vector를 구성합니다.
수식과 기호로 정리하면 다음과 같습니다.
- 시점 t의 context vector: \(c_t=\sum_{s}\alpha_{t,s}\,h_s\)
5. decoder 전달
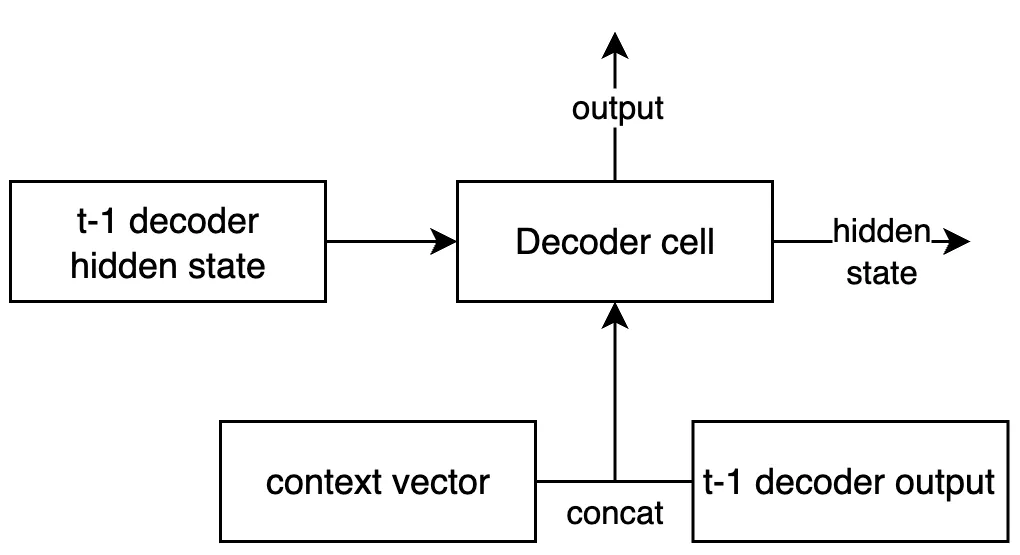
context vector를 decoder에 전달하여 새로운 시퀀스를 만듭니다.
context vector와 직전의 decoder output을 concatenate(결합)하여 입력으로 활용합니다.
이번 시점의 hidden state와 output은 다시 다음 context vector 생성과 decoder의 입력으로 활용됩니다.
Attention은 위와같은 매커니즘으로 모든 입력 시퀀스 정보를 활용하면서, 그때그때 중요한 단어가 무엇인지 학습하는 방법으로 seq2seq의 여러 문제를 해결했습니다. 다음 게시글은 Attention 기반의 아키텍쳐인 Transformer에 대해 알아보겠습니다.