
개요
요즘 많은 서비스에서 자연어 기반 QnA 봇을 사용합니다. 3년 전만 해도 이런 기능은 모델을 직접 학습하기 어려워 도입이 더뎠는데, 요즘은 왜이렇게 많이 보일까요? 그 이유는 RAG의 등장과 발전 때문입니다. 요즘 안쓰이는 분야가 없는 RAG에 대해 자세하게 알아보겠습니다.
기존 LLM의 한계
가장 먼저, RAG라는 개념이 등장하게된 배경부터 시작해보겠습니다.
 출처: https://zdnet.co.kr/view/?no=20230203153950
출처: https://zdnet.co.kr/view/?no=20230203153950
2022년 11월, ChatGPT가 처음 출시되고 두 달 만에 MAU 1억을 달성할 만큼 정말 많은 사용자들이 GPT을 사용했습니다. 사람들은 어떤 질문이던 답을 내주는 GPT에 감탄하면서 검색과 공부에 적극적으로 활용하기 시작했습니다. 예전에는 원하는 정보를 얻기 위해서는 인터넷에 직접 키워드를 생각하고 입력해서 검색 결과를 일일히 찾아봐야하는 노력이 필요했지만, GPT는 단순히 질문을 입력하면 마법처럼 답변을 줬습니다.
그런데 계속 사용하다보니 많은 사람들이 공통적으로 이상한 현상을 경험하게 됩니다. 바로 GPT가 없는 말을 지어내거나 사실이 아닌 내용을 사실처럼 그럴싸 하게 말하는 문제인데, 이것땜에 GPT의 답변을 신뢰하기가 힘들어집니다.
할루시네이션 (Hallucination)
이렇게 LLM이 거짓말을 하는 문제를 할루시네이션, 직역하면 환각 이라고 합니다. 마치 모델이 환각을 보고 거짓을 진실처럼 믿고 답변하는것 같다고 해서 붙여진 단어입니다.
GPT는 새로운 모델을 출시할 때 마다 항상 할루시네이션 현상을 줄였다고 주장했지만, 어떤 모델도 완벽하게 해결하지는 못했습니다. 아무리 노력해도 할루시네이션을 완벽하게 해결하지 못하는 이유는 발생 원인이 모델의 구조적인 문제이기 때문입니다.
현재 GPT를 포함한 대부분의 생성형 모델은 Transformer Decoder 아키텍쳐를 기반으로 동작합니다. 그리고 Transformer는 단어를 생성할때 앞서 어떤 단어가 사용되었는지, 어떤 문맥을 가지는지에 맞춰 “확률적으로” 다음 단어를 예측해 이어 붙이는 방식으로 동작합니다. 우리가 질문을 입력하면 LLM이 질문을 완벽하게 이해하고 알맞는 답변을 하는것처럼 보이지만, 사실은 그냥 질문에 가장 적절한 답변을 “통계적으로” 높은 확률의 단어들을 나열해서 생성하는것에 불과합니다.

그렇다보니 이런식으로 말도 안되는 질문을 해도, 모델은 자신이 가진 정보 중 확률적으로 높은 답변을 생성하다보니 우리가 보기에는 말도 안되는 답변이 나오기도 합니다.
파인 튜닝 (Fine-tuning)
그래서 사람들은 LLM에게 답변이 필요한 분야의 추가적인 정보를 학습시키는 과정을 거쳐 할루시네이션을 최소화 하려고 하는데, 이를 파인튜닝이라고 합니다.
LLM을 학습할때는 다양한 데이터에서 특정 단어만 구멍내고 맞히게 하거나 특정 문장 뒤 이어질 문장을 맞히게 하는 등 다양한 방법으로 인간의 언어를 익히게 합니다. 그래서 초기 LLM은 특정 지식에 집중한다기 보다는 언어 자체를 말하는 법을 학습하는것에 가깝습니다.
파인튜닝은 이런 모델에게 특정 지식을 집중적으로 학습시켜 모델이 모르는 질문이 들어와도 새롭게 학습한 정보를 바탕으로 답변할 수 있게 해주는 기술입니다. 그래서 RAG가 등장하기 전까지는 대부분의 기업에서 QnA, 챗봇을 생성할때 파인튜닝을 이용했습니다.
그런데 파인튜닝은 컴퓨팅 자원이 굉장히 많이 필요하다는 단점이 있습니다. 추가 학습을 시키는 작업이니 고가의 GPU가 여러개 필요했고, 자본이 있는 기업에서만 수행이 가능했습니다. 그런데 이런 흐름을 RAG가 완전히 바꾸게 됩니다.
RAG
RAG는 Retrieval Augmented Generation의 줄임말로, 직역하면 검색 증강 생성입니다. 조금 더 쉽게 설명하면 LLM에게 답변을 생성할때 답지를 주는 방법이라고 할 수 있습니다.
이전에는 LLM의 할루시네이션을 잡기 위해 추가 학습을 진행하는 파인튜닝을 수행했지만, RAG는 답변시 참고할 수 있는 답지를 외부에 저장해뒀다가 필요할때 꺼내보는 방식으로 할루시네이션을 해결했습니다.
RAG는 추가 학습을 진행하지 않고 LLM의 생성능력을 그대로 활용하면서 정보만 추가 제공하는 형태이기 때문에 많은 기업에서 챗봇, QnA봇과 같은 기능을 도입할 수 있게 되었습니다.
파이프라인
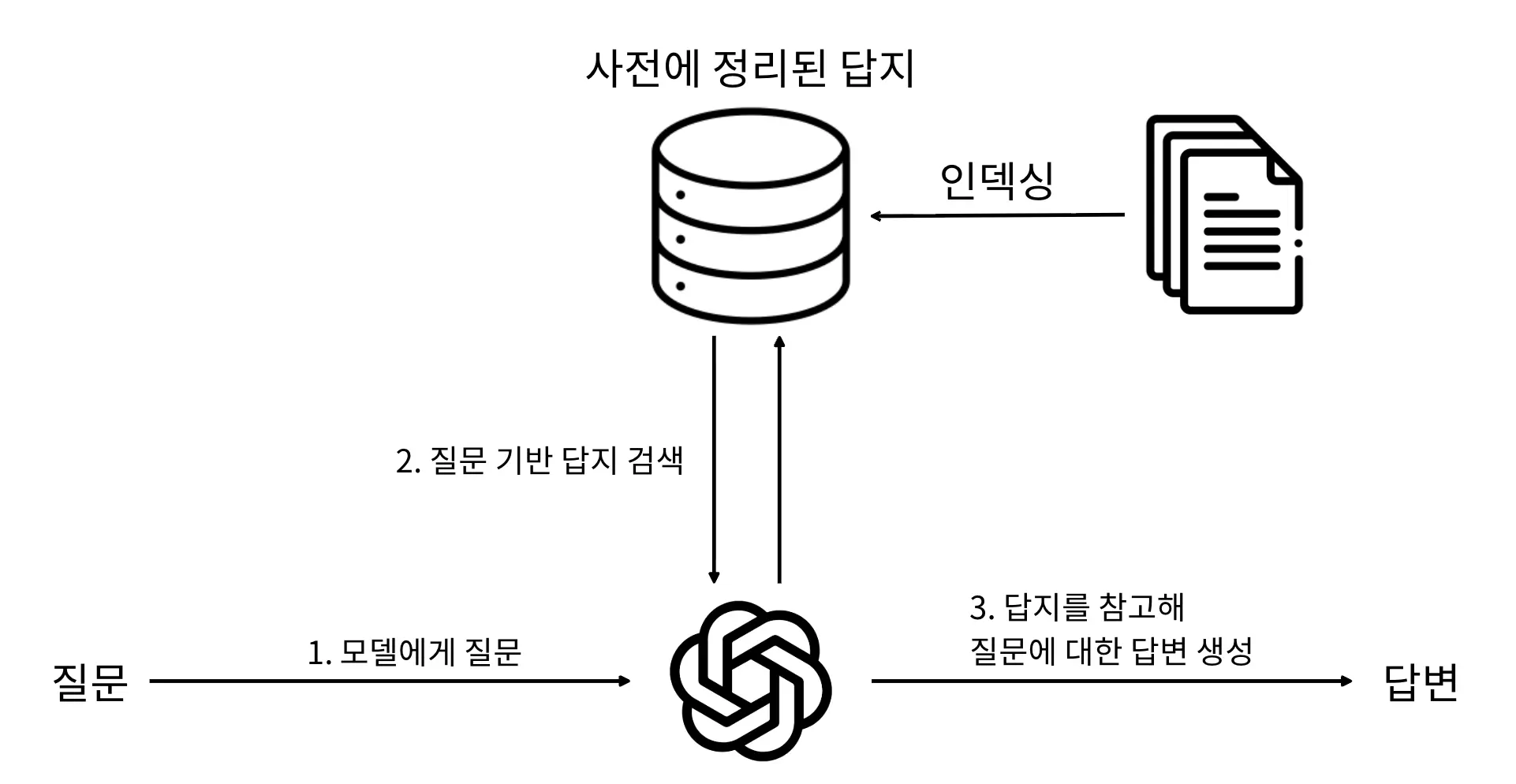
RAG는 크게 색인, 검색, 생성 단계로 나뉩니다.
색인 (Indexing)
답변에 참고할 자료를 미리 정해진 규칙에 따라 분석하고 저장해두는 단계입니다.
모델이 참고할 데이터는 단순히 문서 단위로 저장하지 않습니다. 생성 모델에게 항상 문서를 전부 제공하면, 생성 모델은 어느 부분이 답변에 필요한 부분인지 제대로 식별하지 못해 답변의 퀄리티가 떨어지게 됩니다. 그래서 문서를 정해진 규칙에 따라 나누는 작업을 먼저 진행하는데, 이 과정을 청킹(Chunking)이라고 합니다. 청킹에도 다양한 전략이 있는데, 이 부분은 별도의 주제로 다른 글에서 설명하겠습니다.
청킹이 완료된 문서는 바로 텍스트 형태로 저장하지 않고, 벡터로 변환하는 임베딩(Embedding) 작업을 거쳐 백터화 합니다. 청크를 임베딩 하면 모든 청크는 동일한 차원의 백터로 변환되고, 백터로 변환된 청크와 청크 원본을 묶어 VectorDB와 같은 저장소에 저장해두는것으로 색인은 완료됩니다.
검색 (Rerieval)
검색은 말 그대로 들어온 답변에 맞는 참고 자료를 찾는 단계입니다. 미리 색인해둔 데이터를 질문을 활용해서 참고가 될만한 자료를 찾아오는 과정입니다.
들어온 질문을 이용해 알맞는 자료를 찾을때, 단순히 Full text search로 찾으려면 방대한 양의 데이터에서 검색 성능이 떨어집니다.
그래서 문서를 백터로 변환한 뒤, 백터의 거리를 이용해서 질문과 유사한 청크만 가져오는 방식으로 참고 자료를 찾습니다.
질문도 색인때 사용한 동일한 임베딩 모델로 임베딩해서 백터로 변환한 후, 미리 저장해둔 청크 백터와 거리를 비교해 가장 가까운 N개만 가져오는 방식으로 검색합니다.
색인에서 청크를 미리 임베딩 하는 이유가 이런식으로 검색에 활용하기 위함입니다.
이런 방식을 VectorRAG라고 하는데, 뒤에서 조금 더 자세히 설명하겠습니다.
뒤에 추가로 설명하겠지만, GraphRAG는 검색자의 동작 방식이 조금 다릅니다.
이부분도 뒤에서 설명하겠습니다.
생성 (Generation)
생성도 말 그대로 찾은 청크와 질문을 이용해서 답변을 생성하는 단계입니다. 이부분은 특별한 튜닝 없이 LLM의 생성 능력을 활용합니다. 검색 단계에서 찾은 청크, 질문을 같이 제공하며 프롬프트로 답변을 생성하게 유도하는 방식을 사용합니다.
생성 단계에서는 찾은 청크를 그대로 답변에 활용하지 않고, 사용자의 요구에 따라 변환할 수도 있어야 합니다. 예를 들면, 질문으로 “테스트 결과를 표로 정리해달라” 라는 요청을 하면, 검색 단계에서 테스트 결과 청크를 가져오고, 이 청크들을 그대로 답변으로 내놓는게 아닌 분석하고 요구에 맞게 표로 정리 후 재구성 하는 능력도 있어야 합니다.
그래서 생성 단계에서는 생성 모델의 성능이 매우 중요합니다.
RAG 종류
여기까지 RAG에 대한 등장 배경과 배경 지식에 대한 설명이었습니다. 이제 실제로는 어떤식으로 구현되는지 여러 타입의 RAG를 통해 정리하겠습니다.
VectorRAG
RAG 중 가장 기본적이고 구현이 간편한 RAG입니다. 위에서 설명한 개념이 VectorRAG에 기반한 설명이라서 이미 어느정도 설명이 되었지만 조금 더 자세하게 설명해보겠습니다.
작동 방식
임베딩 모델을 이용해 문서 청크와 질문을 벡터로 변환한 후, 코사인 유사도(Cosine Similarity) 등의 거리를 통해 가장 유사한 청크를 검색합니다. 검색된 청크를 프롬프트에 포함시켜 LLM이 답변을 생성하게 됩니다.
색인시에는 일정한 차원의 백터로 변환된 청크들을 Chroma, Qdrant와 같은 VectorDB를 이용해서 저장합니다. 이때 태그와 같은 메타데이터도 함께 저장하여 검색에 활용하기도 합니다.
장점
- 구현이 간단하고 빠르게 도입 가능
VectorRAG는 다른 RAG 방식에 비해 구현이 매우 간편합니다. VectorRAG는 VectorDB만 준비하면 인덱싱 구현이 가능해서 초기 RAG 실험, 간단한 QnA 봇과 같이 볼륨이 작은 RAG에서 많이 사용됩니다. - 간편한 정보 추가
VectorDB에 임베딩 후 저장만 하면 새로운 정보를 추가할 수 있기때문에 새로운 정보 반영이 간편합니다. - 빠른 검색 속도
VectorRAG는 검색시 질문 임베딩 백터와의 거리만으로 청크를 탐색하기 때문에 검색 속도가 빠릅니다. 그래서 실시간으로 응답과 같이 빠른 응답이 필요한 테스크에서 많이 사용합니다.
단점
- 단순 유사도 기반이라 복잡한 질문에 약함
단순한 임베딩 백터의 유사도만으로 청크를 탐색하기때문에, 여러 청크에 걸쳐 정보를 탐색해야하는 조건에서는 제대로된 검색에 실패할 수 있습니다. RAG의 생성단계는 어쨌거나 청크를 이용하게 되는데, VectorRAG의 이런 한계로 복잡한 관계의 질문에는 좋지 않은 성능을 보일 수 있습니다. - 의미론적 관계 파악의 한계
임베딩 백터의 유사도에 의존하는 검색 특성상 비슷한 의미나 단어의 유사성을 완벽하게 반영하지 못합니다.
정리하면 VectorRAG는 구현은 간편하나 복잡한 질의에는 한계가 명확한 방식입니다.
GraphRAG
GraphRAG는 문서를 단순한 청크가 아닌 그래프 구조로 변환하여 엔티티(Entity)와 엔티티 간의 관계를 명시적으로 저장하고 활용하는 방식입니다. VectorRAG가 복잡한 관계를 파악하지 못하는 한계를 극복하기 위해 등장했습니다.
작동 방식
색인 단계에서 문서를 단순히 청킹하는 것이 아니라, LLM을 이용해 문서 내에서 등장하는 주요 개념(엔티티)과 그들 사이의 관계를 추출합니다.
예를 들어 “애플의 CEO인 팀 쿡이 신제품을 발표했다”는 문장에서 애플, 팀 쿡, 신제품이라는 엔티티와 CEO, 발표라는 관계를 추출해 그래프 형태로 저장합니다.
이때 생성되는 그래프를 지식 그래프(Knowledge Graph)라고 합니다.
이런 그래프는 Json 형태로 파일시스템에 저장하거나, Neo4J와 같은 그래프 DB를 이용해 저장합니다.
검색 단계에서는 질문에서 핵심 엔티티를 파악한 후, 그래프를 탐색하며 연결된 관련 엔티티와 관계 정보를 수집합니다. 이 과정을 통해 단순 유사도 검색으로는 찾기 어려운 여러 단계에 걸친 관계도 추적할 수 있습니다.
장점
- 복잡한 관계 질문에 강함
“A가 B에 영향을 미쳐서 C가 발생한 이유는?”처럼 여러 개념을 가로지르는 질문도 그래프 탐색을 통해 효과적으로 답변할 수 있습니다.
VectorRAG의 가장 큰 약점인 다중 홉(Multi-hop) 질문에서 특히 강점을 발휘합니다. - 문서 간 연결 관계 파악
여러 문서에 흩어져있는 관련 정보를 엔티티-관계 그래프로 연결해두기 때문에, 문서 범위를 넘나드는 질문에도 정확하게 대응할 수 있습니다. - 글로벌 요약 질문에 적합
“전체 문서에서 가장 자주 등장하는 주제는 무엇인가?”처럼 넓은 범위를 아우르는 질문에 강합니다. 이는 VectorRAG가 특정 구간의 유사도만 보는 것과 대비됩니다.
단점
- 높은 색인 비용
색인 단계에서 LLM을 이용해 엔티티와 관계를 추출하기 때문에 VectorRAG에 비해 훨씬 많은 비용과 시간이 소요됩니다.
대량의 문서를 처음 색인할 때 특히 부담이 됩니다. - 엔티티 추출 품질에 의존
그래프의 정확도가 결국 LLM이 엔티티와 관계를 얼마나 정확하게 추출했느냐에 달려있습니다.
추출 과정에서 오류가 발생하면 이후 검색 결과 전체에 영향을 줄 수 있습니다. - 단순 질문에서는 오버스펙
단순한 사실 확인이나 키워드 검색 수준의 질문에는 VectorRAG 대비 이점이 없고, 오히려 복잡한 구조 때문에 응답 속도가 느릴 수 있습니다. 경우에 따라서는 오히려 VectorRAG보다 부정확한 답변이 나오기도 합니다.
정리하면 GraphRAG는 문서 간 관계가 복잡하거나 다중 홉 추론이 필요한 시나리오에서 강력하지만, 비용과 구현 복잡도가 높은 방식입니다.
Hybrid RAG
Hybrid RAG는 벡터 기반 의미 검색과 키워드 기반 검색을 결합하여 각각의 약점을 보완하는 방식입니다. VectorRAG 단독으로는 정확한 키워드 매칭이 어렵고, 키워드 검색 단독으로는 의미적 유사성을 파악하지 못하는 한계를 동시에 해결합니다.
작동 방식
색인 단계에서 동일한 청크를 VectorDB와 키워드 검색 엔진 양쪽에 모두 저장합니다.
검색 단계에서는 들어온 질문을 두 가지 방식으로 동시에 검색합니다.
벡터 검색으로는 의미적으로 유사한 청크를, 키워드 검색으로는 질문에 포함된 특정 단어와 정확히 일치하는 청크를 각각 가져옵니다.
두 검색 결과를 RRF(Reciprocal Rank Fusion)와 같은 알고리즘으로 합산해 최종 검색 결과를 만든 뒤, 필요에 따라 Re-ranking 모델로 순위를 재조정하기도 합니다.
장점
- 검색 정확도 향상
“GPT-4o의 context window 크기”처럼 정확한 단어 매칭이 중요한 질문은 키워드 검색이 강점을 발휘하고, “언어 모델의 입력 한계에 대해”처럼 의미 기반 검색이 필요한 질문은 벡터 검색이 보완하는 식으로 서로의 약점을 채워줍니다. - 다양한 질문 패턴에 대응
사용자 질문의 패턴이 다양할수록 단일 검색 방식으로는 커버하기 어려운 경우가 생깁니다. Hybrid RAG는 두 방식을 동시에 활용하기 때문에 넓은 범위의 질문에 안정적으로 대응할 수 있습니다. - 실무 도입 용이
이미 구축된 키워드 검색 인프라가 있다면 VectorDB를 추가하는 방식으로 비교적 쉽게 도입 가능합니다.
단점
- 인프라 복잡도 증가
VectorDB와 키워드 검색 엔진을 별도로 운영해야 하기 때문에 인프라 관리 비용이 늘어납니다. - 결과 병합 방식 튜닝 필요
두 검색 결과를 어떤 비율로 합치느냐에 따라 성능이 크게 달라집니다.
최적의 가중치를 찾는 과정이 필요하며, 데이터 특성에 따라 달라질 수 있습니다. - 검색 지연 증가 가능성
두 가지 검색을 동시에 수행하고 결과를 병합하는 과정이 추가되기 때문에, 단순 VectorRAG에 비해 검색 지연이 발생할 수 있습니다.
정리하면 Hybrid RAG는 단일 검색 방식의 한계를 실용적으로 극복한 방법으로, 서비스 품질이 중요한 프로덕션 환경에서 많이 선택하는 방식입니다. LightRAG, RAG Anything과 같이 HybridRAG의 개념을 응용한 다양한 논문도 있습니다.
Agentic RAG
Agentic RAG는 LLM을 단순한 생성기가 아니라 에이전트로 활용하여, 검색 계획부터 실행까지 스스로 판단하고 반복하게 하는 방식입니다. 앞서 설명한 RAG들이 고정된 파이프라인을 따른다면, Agentic RAG는 이 흐름 자체를 LLM이 동적으로 결정합니다.
작동 방식
사용자의 질문이 들어오면 에이전트 LLM이 먼저 질문을 분석하고 어떤 정보가 필요한지를 스스로 판단합니다.
그 다음 검색 도구를 호출해 관련 청크를 가져오고, 가져온 정보로 답변이 충분한지 평가합니다.
정보가 부족하다고 판단하면 질문을 분해하거나 검색 키워드를 바꿔 추가 검색을 반복하며, 충분한 정보가 모였다고 판단했을 때 최종 답변을 생성합니다.
이 과정에서 단순 RAG 검색 외에도 웹 검색, 계산기, 코드 실행과 같은 여러 도구를 함께 활용하는 경우도 많습니다.
장점
- 복잡한 다단계 질문 처리
“A, B, C를 비교해서 우리 상황에 맞는 것을 추천해달라”처럼 여러 단계의 추론이 필요한 질문도 에이전트가 스스로 필요한 정보를 순서대로 수집하며 처리할 수 있습니다. - 동적 검색 전략
질문의 특성에 따라 어떤 도구를 쓸지, 몇 번 검색할지를 스스로 결정하기 때문에 고정된 파이프라인 방식보다 유연하게 다양한 상황에 대응할 수 있습니다. - 자기 교정 능력
검색 결과가 기대에 미치지 못하면 스스로 전략을 바꿔 재시도하기 때문에, 단순 RAG에서 발생하는 검색 실패를 어느 정도 자체적으로 보완합니다.
단점
- 높은 LLM 호출 비용
검색 계획 수립, 각 검색 단계 판단, 최종 생성까지 LLM이 여러 번 호출되기 때문에 토큰 비용이 급격히 늘어납니다.
간단한 질문에도 비용이 발생한다는 점에서 비효율적일 수 있습니다. - 응답 지연
반복적인 검색과 판단 과정이 추가되기 때문에 응답 시간이 길어집니다. 실시간 응답이 중요한 서비스에는 적합하지 않을 수 있습니다. - 예측 불가능한 동작
에이전트가 스스로 판단하는 특성상 동일한 질문에도 매번 다른 경로로 답변을 생성할 수 있으며, 드물게 무한 루프에 빠지거나 잘못된 판단을 내릴 위험도 있습니다.
정리하면 Agentic RAG는 복잡한 추론이 필요한 고난이도 질문에 가장 강력하지만, 비용과 응답 지연을 감수해야 하는 방식으로 상황에 따라 신중하게 선택해야 합니다.
RAG의 등장 배경, 구성, 파이프라인, 종류에 대해 알아봤습니다. 다음은 제가 RAG 구현시 평가 지표로 활용했던 RAGAS에 대해 작성해보겠습니다.